





What Is Data Parsing? A Comprehensive Guide

If you work in an industry that heavily relies on digital technologies, you must have noticed vast amounts of data used for research and development. Big Data is now used in medicine to improve diagnosis and illness prediction; cybersecurity professionals extract data from intrusion detection system log files, firewalls, and antiviruses to understand cyberattacks; digital marketing gurus overview social network posts to get a glimpse of consumer sentiment. We could go on.
Using factual and verifiable data to optimize business operations is called data-driven decision-making. At first glance, it may sound straightforward. In reality, it involves data scientists, engineers, developers, and a variety of software tools and know-how.
One of them is a data parsing tool. With a data parser, you will save countless days, weeks, or even months going through abundant information on the World Wide Web. But before we go deeper into all the ways to streamline your data analysis, let's overview what data parsing is and how it optimizes the data analysis process.
What Is Data Parsing?
Imagine you are in a huge library looking for a specific book. Furthermore, the books are all randomized, with science fiction novels mixed with cooking manuals. Going over the shelves and checking books one by one is not the most effective way to do this. You will most likely go to some catalog or use their software tool to search by author or book's name, topic, etc. Data parsing follows a similar logic.
The data parsing process takes vast amounts of unstructured data from websites, databases, or other data repositories. It converts it to structured or more structured data, making it readable and accessible to human viewers and computer programs. It's about turning disorganized data strings into a data format that can be used for analysis.
This conversion requires data parsing tools that you can either build yourself or buy from software developers. Buying a data parser lets you start working with relevant information immediately. However, some of them are very costly and may need more customization options.
On the other hand, building your own parser gives you more control over it. You can set the exact data format your data parser must use to return the results. You will also save money, but only if your developers are skilled enough to code data parsing tools. Some of them are as simple as HTML document scrapers. Others are extraordinarily complex, like C++ compiler parsers.
But the underlying logic remains the same. Like in the chaotic library example, a data parser "looks" at information, often unstructured and with errors, and turns it into a neat catalog, like a parse tree structure. Its very first step is lexical analysis, which breaks down raw HTML data into meaningful tokens (called tokenization), like numbers, symbols, or letters.
It is followed by a syntactic analysis that uses pre-set rules to understand the relationships between these tokens. When analyzing HTML documents, syntactic analysis uses HTML rules to separate tags, syntax elements, headers, meta attributes, and text content strings. This way, it creates specific data structures that only involve required information, eliminating unnecessary components.
Benefits of Data Parsing
Numerous benefits of data parsing exist. We want to outline that modern data analysis is hardly possible without data parsing tools. According to statistics, 3.5 quintillion bytes of information will be created daily in 2024, so manually going over it is Sisyphean labor. Let's overview data parsing benefits in more detail.
Automate Repetitive Tasks
Of course, you can go over chaotic HTML computer code to mark relevant information and collect and store it in a text document. However, this approach is extremely time-consuming, prone to human error, and incompatible with contemporary data analysis software. Instead, your data parser uses predefined rules to overview information sets automatically, eliminating human error and returning the results in organized JSON, XML, and CSV formats.
Streamline Data Analysis
You can use versatile data parsing tools to specify what information you seek and how it should be structured. This is a discussion with your data analysts and their preferred software that accepts information in a specific data format. Once your parser turns unstructured data into a human(or data analysis software)-readable format, you can immediately proceed with the next step.
Save Time and Money
This one is self-explanatory. Data parsing saves costly human resources, and you dedicate your or your employee's time to more important tasks. Furthermore, once you master data parsing, you will establish predefined rules for specific scenarios. For example, you can customize one data parser to get data from HTML documents, like websites, social media activity, emails, etc. Simultaneously, a different data parser can target computer code to extract functions, specific code elements, commentaries, etc.
Reduce Human Error
Like with most computer software, data parsing eliminates human errors. Because working with large data sets is tiresome, mistakes in spreadsheets are all too common. Your data parser will stay energized and accurately collect and structure data for further use. Furthermore, HTML code must often be corrected, like unclosed tags, multiple line breaks, and missing alt text. Someone unfamiliar with HTML may overlook these mistakes and miss essential data units. Meanwhile, you can "inform" your data parser of such errors to increase its accuracy.
Better Storage Efficiency
Unstructured data takes up a lot of space. If you collect relevant information simply by copying it and storing it on your servers, you collect valuable and useless information simultaneously. Regarding Big Data, it can consume terabytes of server storage space, which is costly. When you parse data, you remove unnecessary elements, reduce file size, and can get a cheaper server hosting plan or even use your own server to store compact structured data and save even more money.
Data Parsing vs. Data Scraping
Mistaking data scraping and parsing is easy because they are often intertwined. Both processes focus on automatically extracting data from a source, in contrast to manual data gathering and analysis. Furthermore, data scraping frequently involves data parsing at later stages. Here's how it works.
What Is Data Scraping?
Web scraping is the process of automatically gathering information from websites or other online sources. It sounds easier said than done.
Because there's so much information online, data scrapers require specific website targeting instructions and must comply with lawful regulations, such as the General Data Protection Regulation (GDPR) in Europe. Remember the unfortunate Cambridge Analytica scandal? The company illegally gathered 50 million Facebook user data for political advertisements in the 2016 US presidential elections, resulting in one of the biggest online privacy violations.
After you've taken care of scraping legality, you have another issue. Websites do not like to be scraped. Even if they store publically available data, like product reviews or commodity prices, many websites consider scraping uncompetitive, even if they scrape other online sources at the same time. They implement CAPTCHAS and IP restrictions to deny access.
To overcome these boundaries, web scrapers use residential proxies to rotate between IP addresses and avoid identification. Meanwhile, data parsing is the process that does not require additional anonymization because it works with existing data sets, transforming them from one format to another.
Scraping and Parsing Key Differences
To be faithful to definitions, separating data scraping and parsing is best, so here are their key differences.
1. Focus. Data parsing involves converting data from one format to another, and data scraping involves automatically collecting it from websites or other online sources.
2. Output. Web scraping usually returns a string of HTML code. Meanwhile, data parsing returns more organized file formats, like JSON or CSV.
3. Internet access. Data scraping requires Internet access to target websites. On the other hand, your data parser can perform while being fully offline.
4. Dependence. Web scraping does not require parsing if it collects small amounts of easily interpretable data. In contrast, parsing depends on web scraping to get raw data for processing.
As you can see, these processes are two sides of the same coin and work in tandem. However, understanding their key differences helps you select the appropriate technology for the task at hand.
Popular Data Parsing Techniques
Now that we have definitions out of the way let's look at the most common data parsing techniques.
JSON and CSV Parsing
Web applications often utilize the compact JSON (JavaScript Object Notation) data format. JSON has specific rules and organizes data using arrays and key-value pairs. JSON parsers analyze JSON documents following their unique rules to convert them into a preferable data format.
CSV (Comma-separate values) is another widely popular file format. It is made up of strings of plain text that are organized in columns and rows. Each column represents a specific field, and each row is a data record, using commas to separate values in every row. Like in the previous example, a CSV parser follows its unique rules to extract and process the required information for further use.
Regex Extraction
Regex stands for regular expressions. It is one of the more straightforward yet powerful data parsing techniques. It analyses a document of plain text to identify specific patterns using a set of search rules. For example, it can extract product reviews from social network posts in publicly available groups.
String Parsing
String parsing is similar to regex extraction but with a broader scope. It processes text strings into smaller pieces that a computer program can interpret. While regex extraction uses regular expressions to identify patterns, string parsing utilizes multiple techniques, like removing delimiters, tokenization, and identifying structure.
HTML and XML Parsing
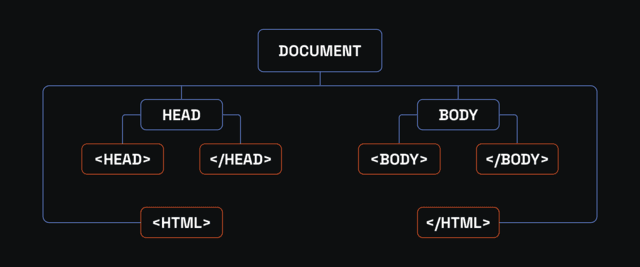
XML and HTML are markup languages for information structuring using different rules. An HTML parser goes over HTML to inspect its tags and elements within tags and returns a Document Object Model (DOM) mapping out their relationships. Similarly, an XML parser reviews XML code with a custom tag and creates a tree-like representation of their hierarchy.
Practical Steps for Using a Data Parser
Like with web scraping, preparing before data parsing is best. Otherwise, you can end up with an organized file full of useless data that you need to overview manually or parse again. Here are a few practical tips to help you along the way.
Pick a Source and Format
To parse data, you must first acquire it. If you're going to parse information from websites, inspect their web scraping permissions, usually outlined in the robot.txt file. We also recommend verifying API access, which is an excellent way of gathering online data without a scraper. At this stage, you should also choose the data format (XML, JSON, CSV, etc.) you will be working on to help you select the correct parsing software or build your own.
Pick a Data Parser
Once you've figured out your data source and format, overview the many data parsing tools on the market. Simultaneously, it would be best to choose additional tools like a web scraper and frameworks like Python's BeautifulSoup or Scrapy, Java's DOM, Node.js Puppeteer, and many others.
Verify Parsing Rules
Parsing is the process dependent on specific data formats. If you buy a parser, ensure it is compatible with your data analysis software. If you choose to develop your own tool, get familiar with specific rules that define XML, HTML, or other types of data. This will help you write efficient functions to gather only useful information.
Collect and Store Data Safely
If you collect publically available web data, you must ensure you do so legally. For example, if you scrape websites that use personally identifiable information (name, surname, workplace, etc.), it's best to depersonalize it before saving it on your servers. As we've mentioned previously, online data gathering is regulated by the GDPR in Europe or the Californian Consumer Privacy Act (CCPA) in the US.
Simultaneously, ensuring server safety is paramount. Imagine losing terabytes of business intelligence due to a flood, fire, or other natural disaster. You can order a reliable server hosting service or use the 3-2-1 backup rule if you store data on our own servers: have 3 data backups in 2 different media, with 1 being an offline backup.
Real-Life Examples of Data Parsing
Numerous businesses are extracting data to optimize their decision-making, so data parsing can be found almost anywhere. We listed the three common real-life scenarios below to give you a better view.
Price Comparison
Large enterprises and price comparison websites use data parsing to get commodity prices, features, and special discounts from their competitors or online stores. It is often done as a part of broader web scraping operations to narrow down useful data and get the result in an organized fashion.
System Log Analysis
Cybersecurity experts and system administrators use parsing to extract the required information from system or cybersecurity software logs. Because these logs contain all system events and issues, they are extraordinarily hard to read manually. Instead, IT professionals use data parsers to target specific elements and predict network failures.
Chatbots
Modern chatbots parse conversations to identify keywords and present an accurate answer. Virtual assistant and chatbot parsers analyze the sentence structure to determine the exact query. This helps to reduce human discourse to data strings entirely understandable by computer software.
Common Challenges in Data Parsing
Working with large data sets is challenging and requires keen attention. Furthermore, gathering online data carelessly can get you in legal trouble, resulting in expensive lawsuits like the LinkedIn vs. HiQ case. Here are some of the most common data parsing errors.
Ethics and Cybersecurity
It's always best to refrain from scraping and parsing personally identifiable data. However, if your business model relies on PII, you should take additional steps to keep this information safe. Such data cannot be used to target real people with advertisements without their consent. It must be stored safely to prevent data leaks and unauthorized access.
Scalability
The more data you use, the more computational power you require. If your data parser has too broad data analysis rules, it will waste your resources struggling through a large file. Furthermore, consider the humongous amounts of daily data generated online and define important segments to reduce bandwidth consumption while scraping.
Incomplete Data
You will sometimes encounter data sets full of errors. Faulty HTML code leads to parsing errors and provides distorted results, which can have dire consequences when used for further analysis. Validating the data set before fueling it into your data parsing software will ensure the process is free of errors.
Changing Data Sources
Progressive websites evolve over time, which means they can change their API structure, programming language, frameworks, etc. It is best to check the website code regularly because otherwise, you might miss essential changes, resulting in many parsing errors.
Final Thoughts
Whether you're a business owner, IT professional, or marketing expert, data parsing can optimize numerous tasks. As the saying goes, data is the new gold. All of the Big Tech is crazy about gathering online user data, sometimes stepping into the illegal to get this precious commodity.
Instead, we recommend following data-gathering ethics. You will notice that ethical web scraping and accurately defined data parsing provide invaluable insights without crossing legal boundaries. Furthermore, it saves time and human resources you can allocate elsewhere, leaving this neat automatic process running in the background.


