

Amazon is a goldmine of data. Prices, reviews, rankings, specs, and even product descriptions: it’s all right there, publicly available, just waiting to be collected. But try to scrape it, and you’ll hit a wall fast.
Why?
Because Amazon doesn’t just watch what you request - it watches how you request. This website has some of the most advanced anti-scraping measures on the web to stop you. It checks your IP address, identifies your user agent, tracks your behavior over time, and personalizes dynamic content based on your region. Without a plan and proper setup, your web scraping attempt will fail before it even begins.
In this guide, we’ll show you how to scrape Amazon product data using Python without getting flagged or blocked. Our code examples will work with the requests library, use smart headers, apply IP rotation, and save our scraped data to a clean CSV file, step by step.
Step-by-step guide to scraping Amazon data
Let’s build a simple Amazon web scraping tool together, one that scrapes product titles, URLs, prices, ratings, reviews, and images from Amazon’s Best Sellers page for phone cases in the US store. We chose this niche because it’s specific enough to keep things clean, but also common enough to show how powerful even a small scraping setup can be.
So here’s what we’ll do: gather data from the first 60 listings on that Best Sellers page, enough to trigger pagination, and observe how the Amazon website handles repeated requests. It’s a realistic test case that provides a meaningful dataset and a chance to see what works (and what doesn’t) under pressure.
Here’s the data we’ll pull for each product:
- Title
- URL
- Price
- Star rating
- Number of reviews
- Image URL
This is just one example. The same logic applies whether you’re gathering product titles from kitchen gadgets, tracking price changes on headphones, or collecting product URLs for gaming accessories. Follow along, and by the end, you’ll have a working Python web scraping file you can tweak for your own data collection needs.
Ready? Let’s write some code.
Step 1: Setting up the environment
Before we start sending requests or parsing product details, let’s pause for a quick setup check. You’ll need Python installed on your system, a few core libraries ready to go, and a folder to hold your scripts.
This part is quick, but it saves you from getting weird errors midway through the scrape.
- Make sure Python is installed
We need Python on your machine. If you’re not sure whether it’s installed, open your terminal and type the line below. If you get an error, visit python.org and grab the latest version for your OS, then try again.
python --version
If installed, you should see the Python version your device is running. Here's ours:
- Choose a location for your folder
To keep things organized, let’s select a location to store the folder for this project. You can store it anywhere. We’ll use the Desktop in this example. In your command prompt, type:
cd Desktop
That just tells your machine, “Hey, this is where I want the new folder to go.” Below is our output:
- Create a new folder
Next step: create the folder. This is where your Python script, your scraped data, and your working files will stay. In your command prompt, type:
mkdir amazon_scraper
You should see the following:
- Enter the new folder
Let’s move into the folder you just created. That way, every script you write and every product title you extract will get saved in one clean place. Type this command in the next line:
cd amazon_scraper
You should see the following:
- Install the required libraries
We’ll need three libraries for web scraping: requests to handle HTTP calls, beautifulsoup4 to extract product details from HTML, and fake-useragent to help spoof browser headers and reduce the risk of being blocked. You can install them all at once using this line:
pip install requests beautifulsoup4 fake-useragent
It might take a minute or two to complete:
- Write the starter Python script
Keep your terminal open, we’ll return to it. Right now, shift gears and open your code editor of choice. From there, navigate to the folder you just created and start a new Python file. Call it final_amazon_scraper.py. Then paste this in:
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import csv
import random
import time
print("Environment is ready. Let’s scrape something.")
You can save the file now. Just make sure it’s inside the folder you created earlier. Once it’s saved, flip back to your terminal. We’re going to run it just to confirm everything’s wired up correctly. Paste this script in from where you left off:
final_amazon scraper.py
If all goes well, the script will print, "Environment is ready."
If you saw the message, that means everything’s wired up the way it should be. Python is talking, your libraries are loaded, and we’ve got green lights across the board. Let’s keep that momentum going - time to move on to step 2.
Step 2: Create a reusable user agent generator
We only want to create our fake user agent generator one time. So we do it at the start, right after our imports. The UserAgent() instance provides randomized browser headers on demand through .random. If we created a new generator for every single request, that would be a waste of resources and could slow things down. So instead, we create it once and reuse it cleanly wherever we need it.
Just add this one-liner after your imports:
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import csv
import random
import time
print("Environment is ready. Let’s scrape something.")
ua = UserAgent()
Step 3: Implementing proxy server rotation
Now that we’ve got our script up and running, it’s time to discuss proxy server rotation. Here’s the deal: we’re about to make 100 separate requests to Amazon’s Best Sellers page. That’s 100 requests to the same category within the same timeframe.
The one thing you don’t want to do is send them all from your own IP address. That’s basically like standing outside Amazon’s front door shouting, “Hey, I’m scraping your site! Just me, over and over!” Instead, we want to spread those requests across different IPs so it looks like regular traffic coming from different people in different places.
We’re using five residential proxies from MarsProxies, each with a different location and session string. Why five? Because our script only needs two to three requests per Amazon Best Sellers page. Since we’re scraping up to page two, we’re looking at a max of six requests total. That’s one per IP, give or take. Five proxies = five people casually browsing phone cases. That’s the illusion we’re going for.
Here is what you need to do:
- Configure your rotating residential proxies
If you haven’t already set yours up, log into the MarsProxies dashboard, select ‘Residential’, and pick your first location. We chose Norway and selected Oslo as our city. For the connection type, stick with HTTP and set the session length to 20 minutes. You will then get a list of credentials as shown below:
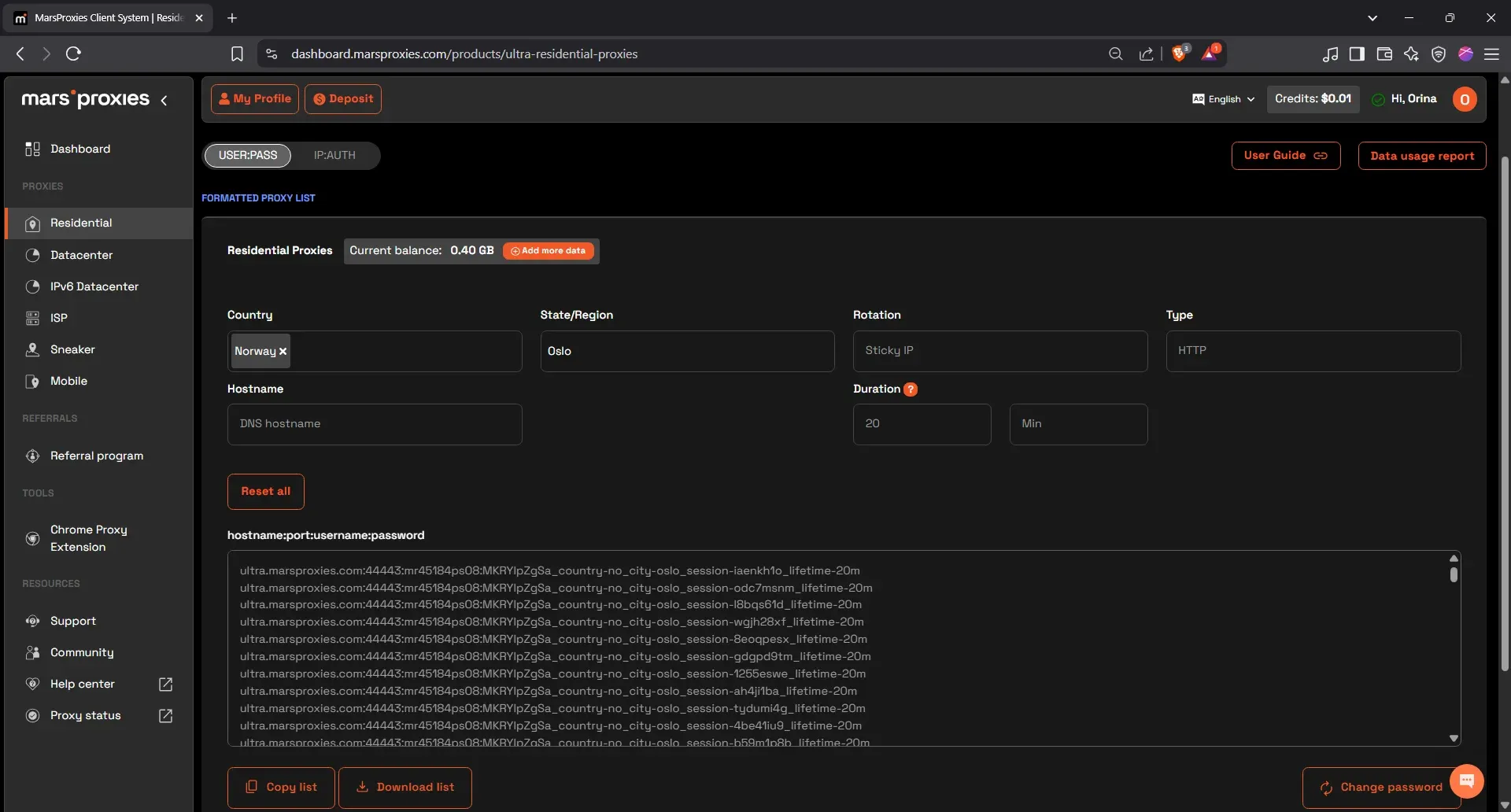
The login credentials look like this:
ultra.marsproxies.com:44443:USERNAME:PASSWORD
Each part of the string represents something specific:

You just need to take one of the lines in the list and convert it to a dictionary holding the HTTP and HTTPS proxy strings like so:
# Proxy pool with the first entry (each includes http and https)
proxy_pool = [
{
"http": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443"
},
Here is how the string is built:
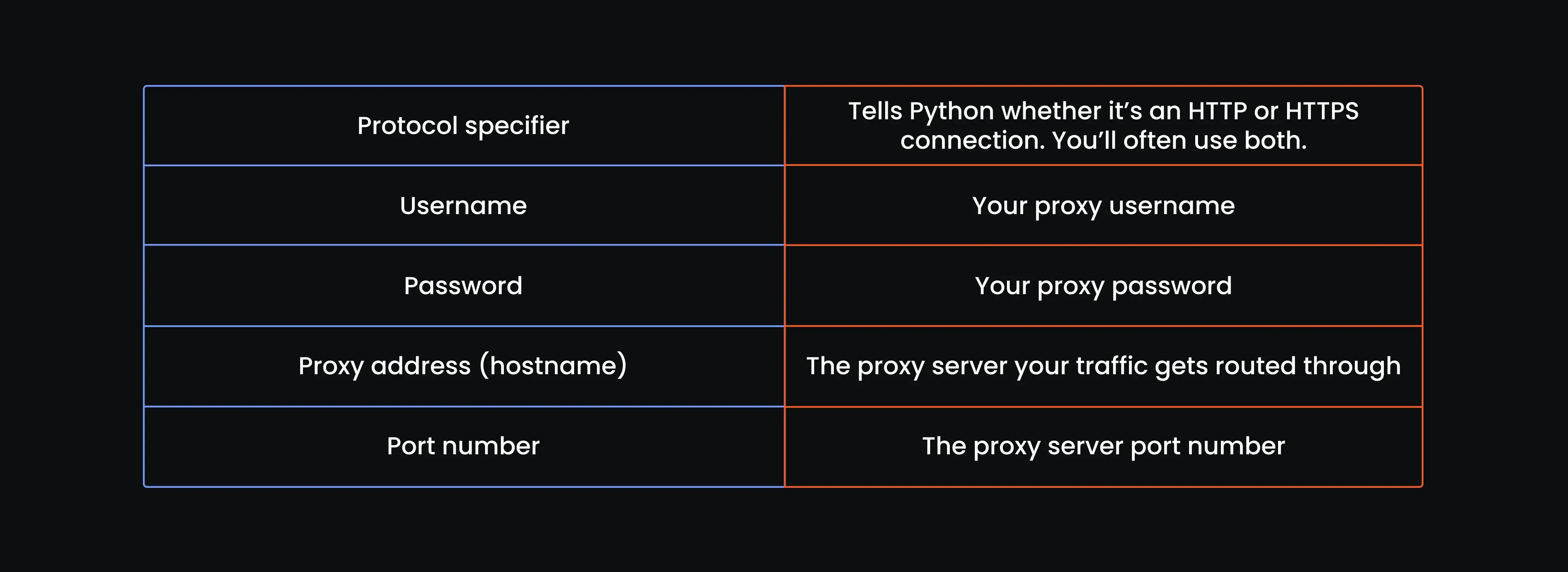
You’ll repeat that structure twice, once for ‘http’ and once for ‘https’ inside a dictionary. That way, no matter what kind of Amazon URL your request hits, you’re covered.
- Choose four more proxy locations
Build the proxy string four more times, one proxy per line. Each time, select a different country and city combination in your MarsProxies dashboard, then get the proxy string, format it into a dictionary with HTTP and HTTPS, and drop it into the proxy_pool list. By the end, you’ll have five of these dictionaries stacked together. That’s your rotation setup. Here is what we have:
# Proxy pool with 5 full proxy entries (each includes http and https)
proxy_pool = [
{
"http": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-us_state-connecticut_session-i2dot8ln_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-us_state-connecticut_session-i2dot8ln_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-gb_city-auckley_session-bcvhavyg_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-gb_city- [email protected]:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-za_city-bloemfontein_session-cs66ctv9_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-za_city-bloemfontein_session-cs66ctv9_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-fr_city-avignon_session-tj4zlg8g_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-fr_city-avignon_session-tj4zlg8g_lifetime-20m@ultra.marsproxies.com:44443"
}
]
- Update your script
Here is the full script up to this point:
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import csv
import random
import time
print("Environment is ready. Scraping started.")
ua = UserAgent()
# Setup user agent generator
ua = UserAgent()
# Proxy pool with 5 full proxy entries (each includes http and https)
proxy_pool = [
{
"http": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-us_state-connecticut_session-i2dot8ln_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-us_state-connecticut_session-i2dot8ln_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-gb_city-auckley_session-bcvhavyg_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-gb_city-auckley_session-bcvhavyg_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-za_city-bloemfontein_session-cs66ctv9_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-za_city-bloemfontein_session-cs66ctv9_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-fr_city-avignon_session-tj4zlg8g_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-fr_city-avignon_session-tj4zlg8g_lifetime-20m@ultra.marsproxies.com:44443"
}
]
The proxy rotation is in, the libraries are loaded, and the environment is clean. Let’s move to step 4.
Step 4: Building your scraping foundation: The request logic
Amazon doesn’t joke when it comes to web scraping activity. This isn’t just any website - it’s the biggest e-commerce platform on the planet. And it knows exactly how valuable its data is. You can bet it’s not just going to let anyone come in and extract it like it’s free candy.
The thing is, Amazon expects people to want that data. It knows third parties attempt to scrape product titles, star ratings, and pricing information for various purposes, including market research and price comparisons.
So, it doesn’t just protect the data. It actively fights you. With dynamic CAPTCHAs, aggressive IP bans, header fingerprinting, TLS checks, and behavior-based triggers that don’t always make sense. If your script feels the tiniest bit robotic? Denied.
That’s why we can’t just send a basic HTTP request and hope for the best. Rotating IPs may get us through the front gate, but to actually walk up to the door without setting off alarms, we need more.
Randomized headers will help us blend in, and the retry system gives our code the resilience to try again when Amazon pushes back. One rejection doesn’t mean the game is over - it just means we change outfits and try again.
#Session setup
session = requests.Session()
#Rules for retrying
retries = 3
delay = 10
success = False
#Main retry logic
while retries > 0 and not success:
user_agent = ua.random
proxies = random.choice(proxy_pool)
print(f"Trying with User-Agent: {user_agent}")
print(f"Using Proxy: {proxies['http']}")
#Natural pause
time.sleep(random.uniform(3, 8))
#Our GET request
try:
response = session.get(
"https://www.amazon.com/Best-Sellers-Cell-Phones-Accessories/zgbs/wireless/2407760011",
proxies=proxies,
timeout=20
)
print(f"Status Code: {response.status_code}")
# Parse the HTML response
soup = BeautifulSoup(response.content, "html.parser")
product_cards = soup.find_all("div", attrs={"data-asin": True})
# Block detection logic
if ("captcha" in response.url or
"[email protected]" in response.text or
soup.find("form", action="/errors/validateCaptcha") or
response.status_code != 200 or
len(product_cards) == 0):
print("Blocked or failed. Retrying...")
retries -= 1
time.sleep(delay)
delay *= 2
continue
# Success condition: If we got here, we passed Amazon’s outer wall
print("Success! Got a response that wasn’t blocked.")
success = True
#Catching request errors and retrying with exponential backoff
except Exception as e:
print(f"Request failed: {e}. Retrying after {delay} seconds...")
time.sleep(delay)
retries -= 1
delay *= 2
Our request logic is a bit long. But it needs to be. It’s doing a lot behind the scenes to make sure we don’t get kicked out on the first knock. Let’s walk through the parts that make this thing tick.
- Session setup
The first thing we do is set up our web scraping session. It's like keeping a browser tab open while you scroll through pages.
- Rules for retrying
Amazon isn’t going to hand us data on the first try, so we plan for rejection. The script gives Amazon three chances to cooperate. If it blocks us, we wait 10 seconds and try again. If that fails, we wait longer.
- Main retry loop
If Amazon doesn’t give us what we want the first time, no problem. The retry loop swaps in a new user agent and a fresh proxy for every attempt. It logs both, so you know exactly how each request is being disguised.
- Natural pause
A short break of 3 to 8 seconds gives our web scraping script just enough time to appear as if someone is thinking or scanning the screen.
- The GET request
We wrap the request in a try block, just in case the whole thing breaks, because it might. We’re sending an HTTP GET request using our persistent session (that browser-like tab we opened earlier). We include the Amazon URL we’re targeting, plug in the proxy we selected, and instruct it to give up if it takes longer than 20 seconds. If Amazon answers? Great. If not? The retry system kicks in and tries again.
- Parsing the response
Before we even think about scraping the bestseller phone cases page, we need to make sure we’re not staring at a fake page. Just because Amazon responded doesn’t mean it gave us the real thing.
Sometimes you’ll get a CAPTCHA or a 200 OK response that’s actually just a pile of placeholder HTML. So the first thing we do after parsing the page with BeautifulSoup is call find_all() on a specific <div> element that contains the data-asin attribute.
Why? Because that’s how Amazon structures its product listings, each product card on the page is wrapped in one of these containers. If this call doesn’t return anything, that’s our early warning: either we’ve been blocked, the page is empty, or Amazon has changed its structure. This check helps us catch bad responses before we waste time trying to scrape air.
- Block detection
First, we ask: has Amazon quietly redirected us to a CAPTCHA page? That’s what ‘captcha’ in ‘response.url’ is checking. Then, we look for signs of a CAPTCHA validation form, search the response for Amazon’s fallback support email, and check if the page gave us any actual product cards to parse.
If any of these checks fail, or if the status code isn’t a clean 200, we treat it as a block. The retry system kicks in, we wait 10 seconds, then 20, then 40. We try again each time, dressed up with a new IP and a new identity string.
- Success condition
If none of the block signals are triggered, we mark the request as successful and exit the retry loop.
- Catch request errors
Errors are part of the game, and this section is how we stay in it. If the request fails entirely due to any other error, such as a timeout, or network issues, we don’t let it crash the program. We catch that error, print the details so you’re not left in the dark, and give it a bit of breathing room before trying again with a new plan.
Step 5: Identifying elements to scrape
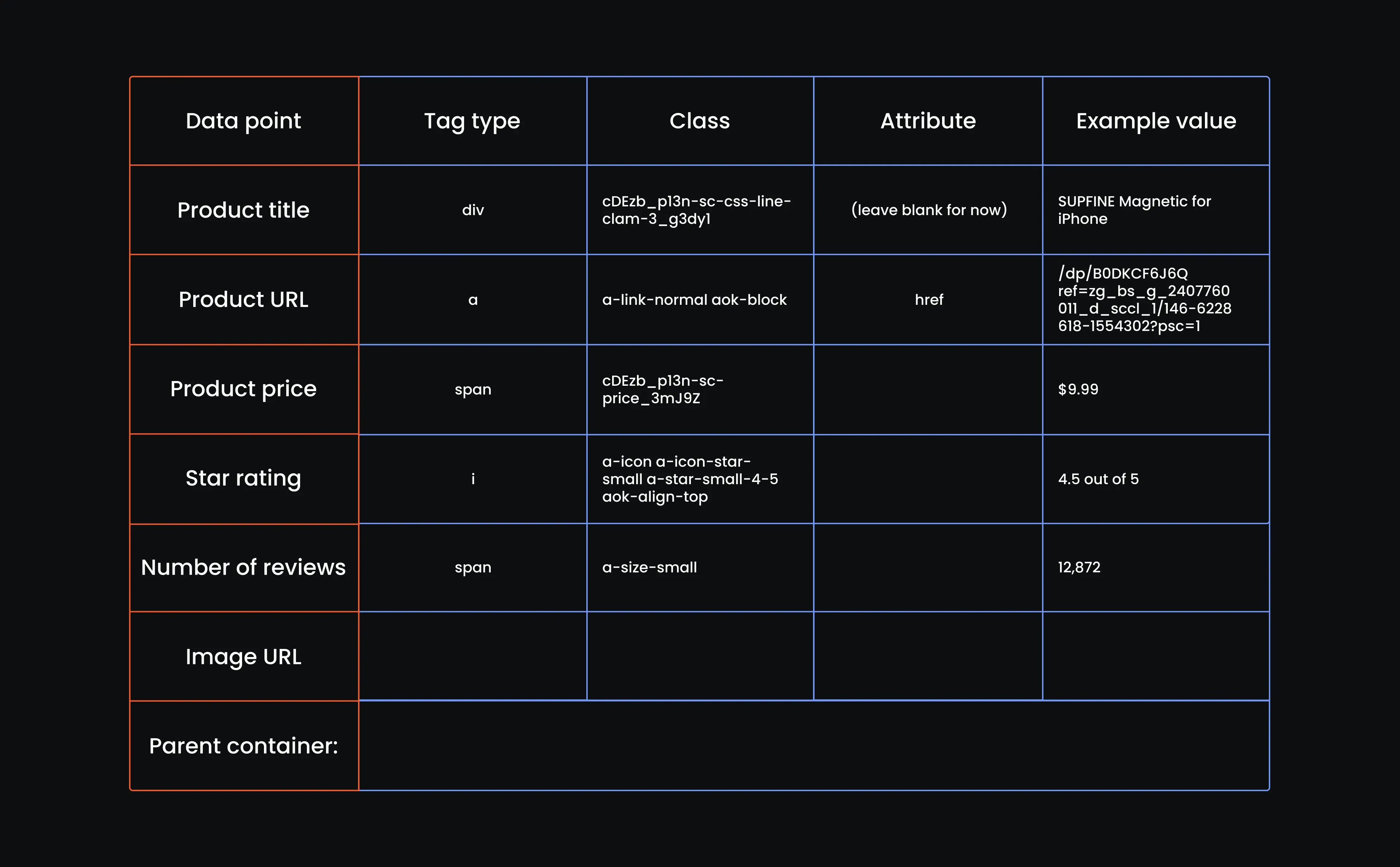
Let's step away from the code for a bit and build our reference table. If you’ve ever looked under the hood of a web page, you know it’s a mess of <div>s, <span>s, and nested tags. This table helps us make sense of it. It breaks down exactly which tag holds each piece of product information, so when we start scraping, we’re not left to guess.
- Create a reference table
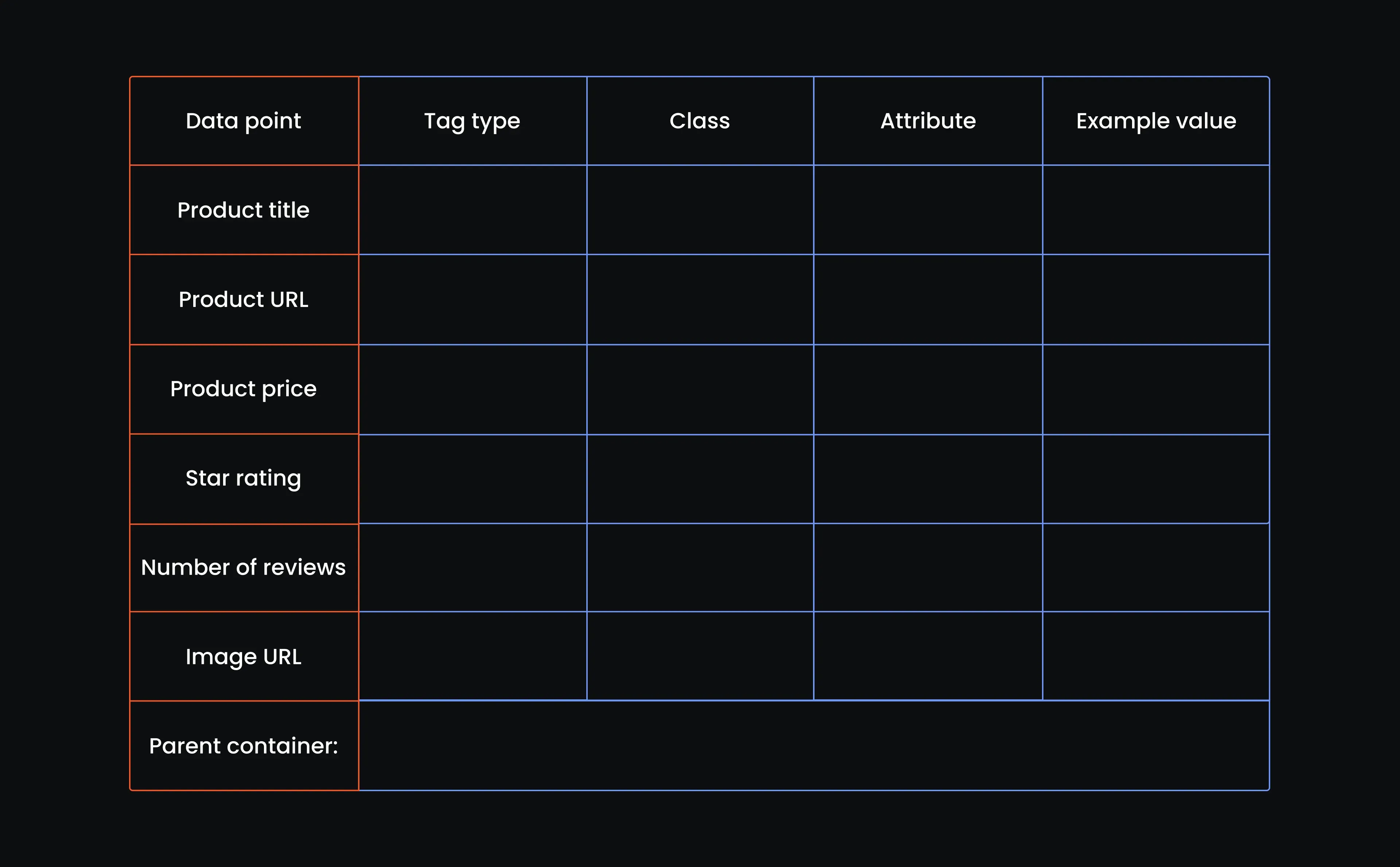
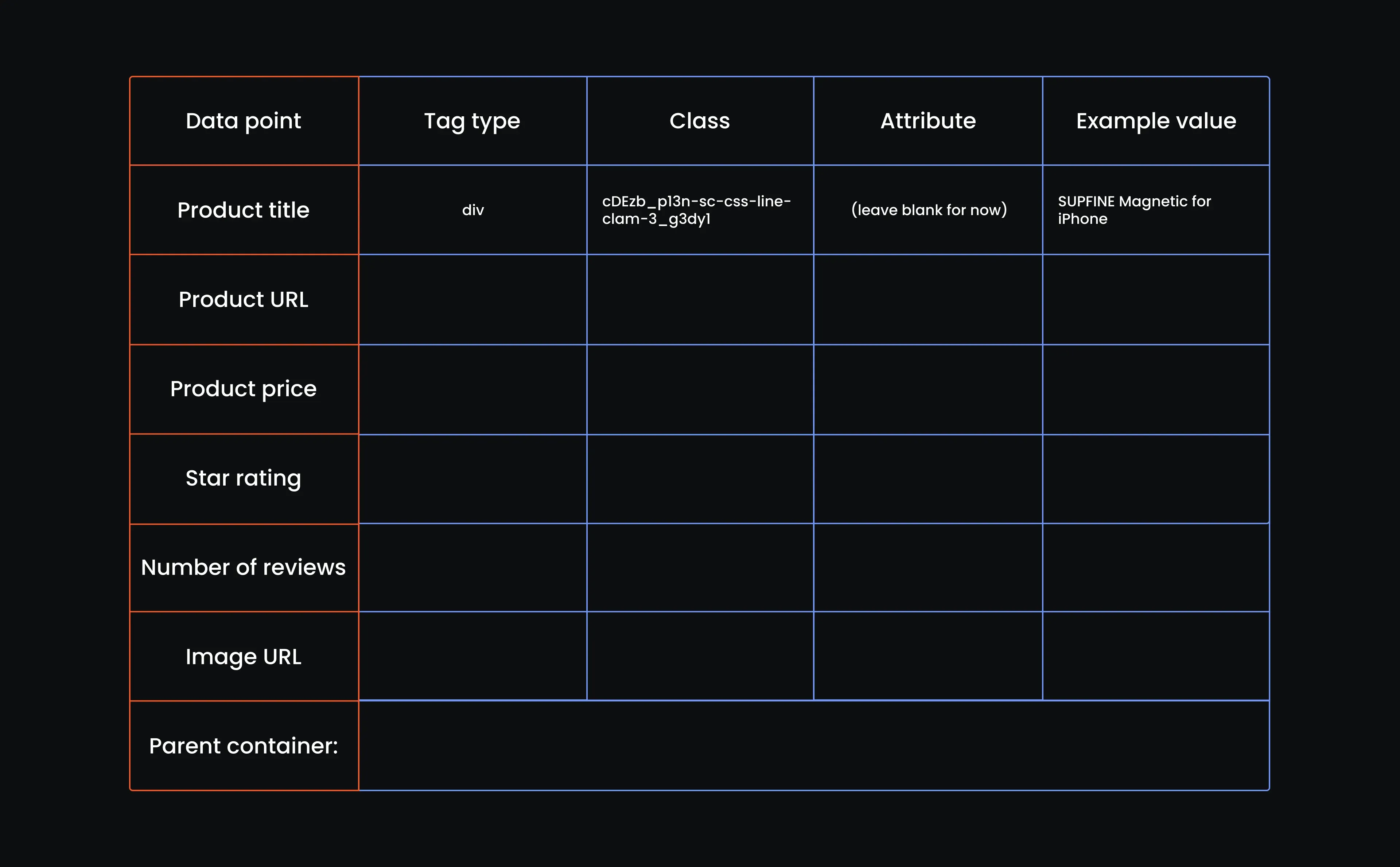
This next step might feel old school, but trust us, it saves you from banging your head on your keyboard later. We’re going to go through the Amazon website manually, look at the HTML structure, and create a reference table.
You just need a table with columns for tag type, class name, attribute, and example value for each piece of product info. It’s like handing your web crawler a flashlight and a floor plan. You want it to know where to go, not blindly wander around. So, create a table with the following attributes:
- Open Amazon US’s phone case best sellers page
Open up your browser, head to the Amazon Best Sellers page for phone cases in the US, and let’s start filling that table out one element at a time. Here's what we have:
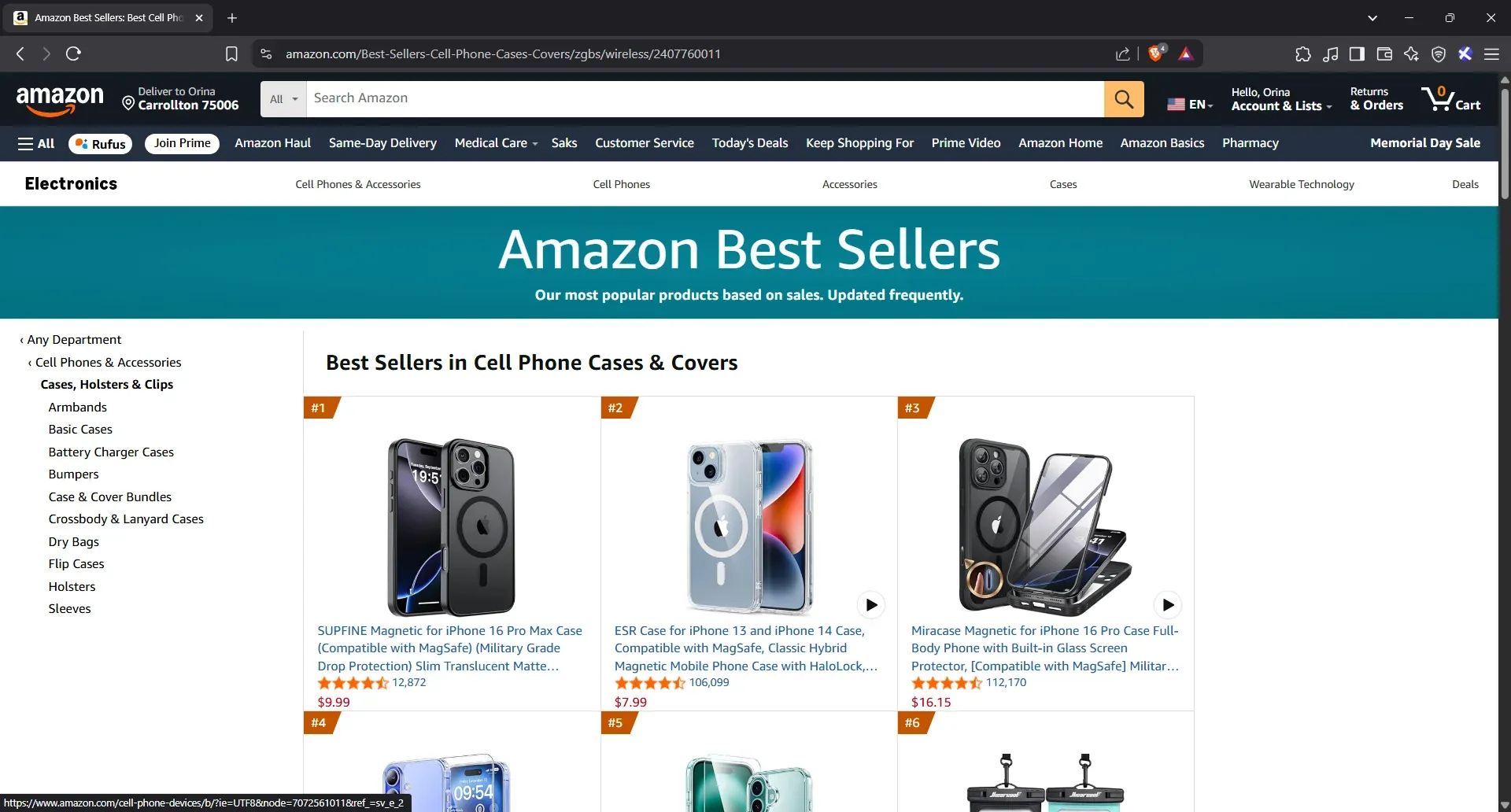
- Inspect the phone case title
You don’t need to do this for every listing. We’re just identifying the structure once. Pick the first phone case you see, right-click on the product title, and select “Inspect” from the dropdown menu. This will open your browser’s developer tools and highlight the HTML element for the title.
- Find the product title HTML line
The HTML will pop up on the right and highlight a specific line. Hover over it. If the product title on the page lights up, you’re in the right spot.
- Extract the product title tag type, class, and attribute
Now, we’re ready to fill in the first row of your reference table. Take a look at the line you hovered over - it’s a <div> nested inside a <span>. That’s the tag we care about.
Copy the full class string exactly as it appears, even if it looks messy. Leave the attribute column blank for now, and for the example value, grab a word or two from the product name that you’ll recognize later when testing. Here's our table with the first row filled out:
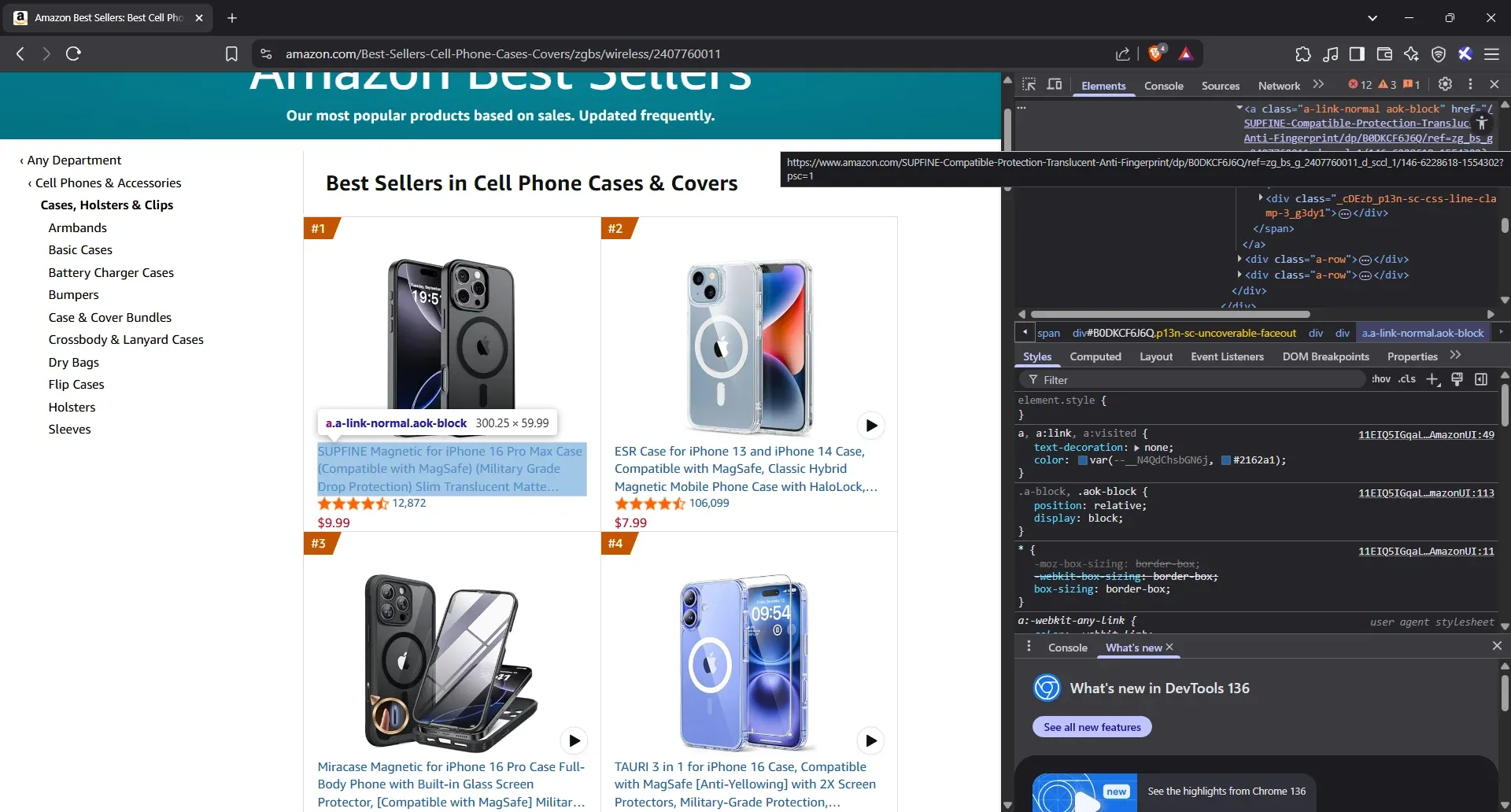
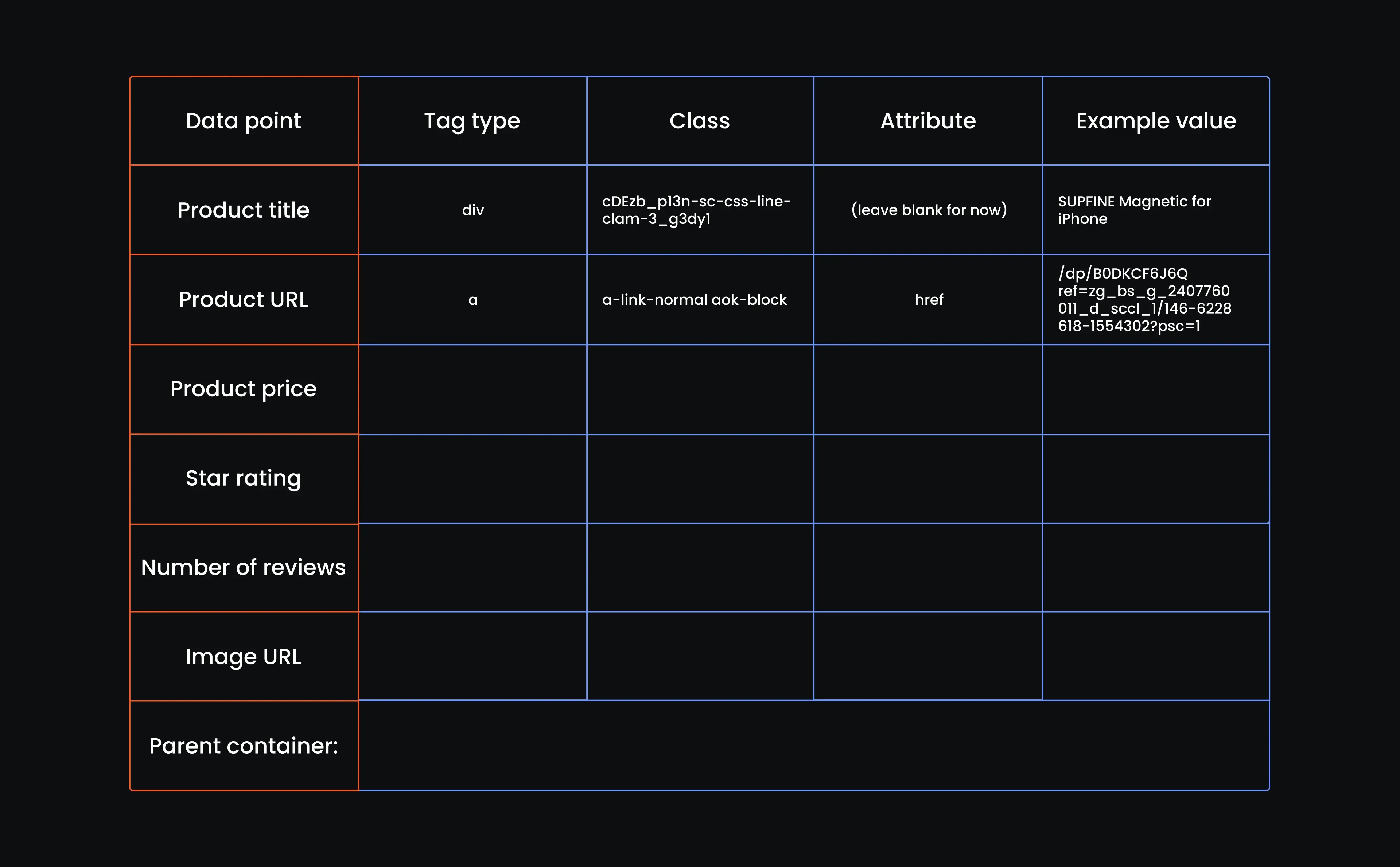
- Inspect the product URL
Move just one line up from the product title’s HTML. You’ll hit a tag that starts with <a. That’s the anchor tag, and it’s what holds the product URL. You’ll know you’ve got the right one if the product title on the page stays highlighted.
- Extract the product URL tag, class, and attribute
Do you see that anchor tag that wraps around the title <div>? That’s our guy. It’s what links out to the product page. So go ahead, fill in the second row with tag a, grab the class name exactly as it appears, and pop href into the attribute column.
- Inspect the product price
Let’s move on to the price. Just right-click directly on the number shown below the title and hit Inspect. You’ll get a fresh HTML line. Hover it. If the price on the page turns blue or gets highlighted, that’s your green light.
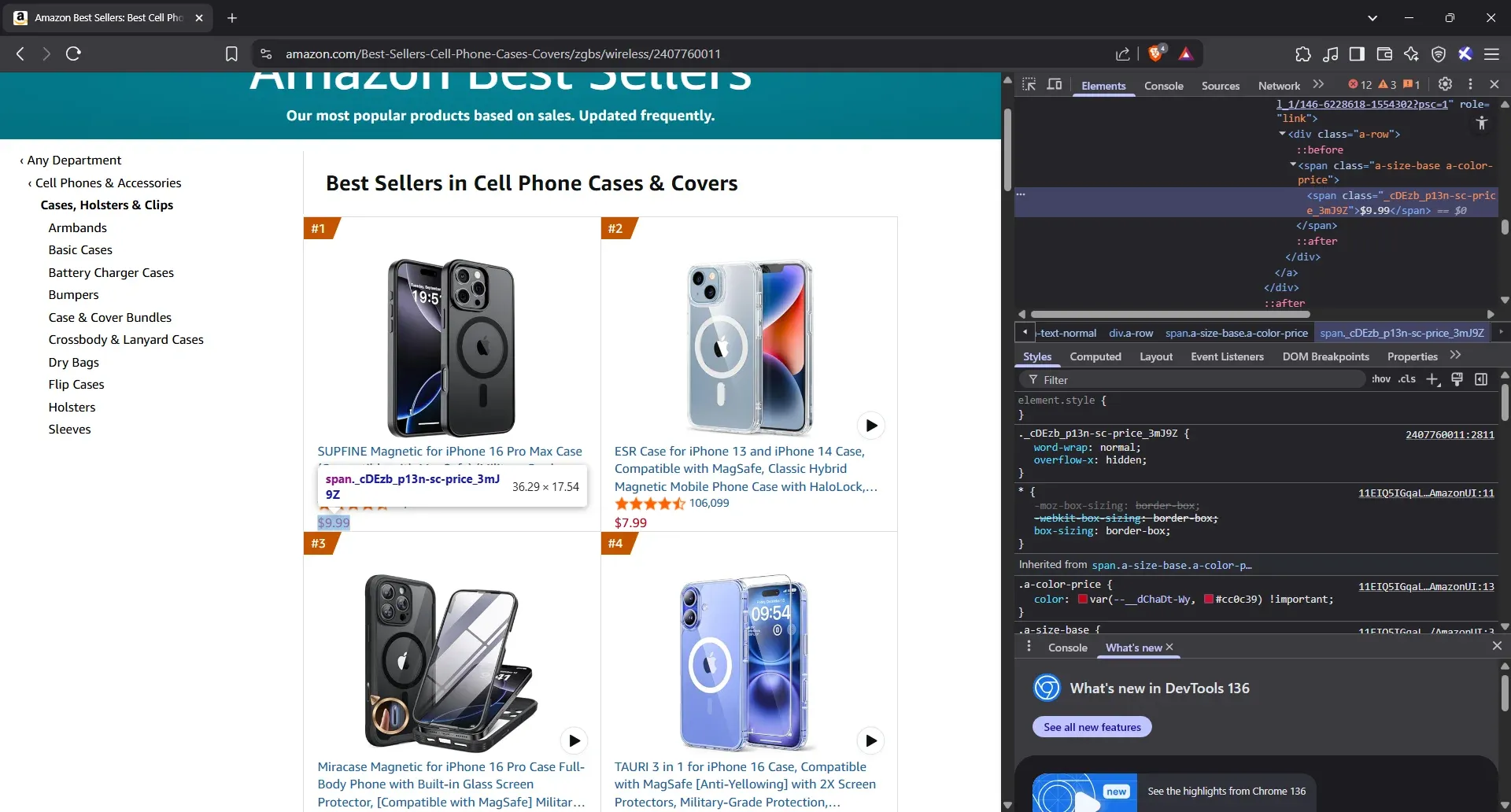
- Extract the product price elements
It’s an easy win here. You’ll see the price sitting cleanly inside a <span> tag. Just grab that, copy the full class name, paste it in, and we’ll move on. You don’t need the attribute here. For the example, just add the price as is. Here is our reference table up to this point:
- Inspect the star rating
Click on the star rating directly below the price, then go ahead and Inspect. Your browser will bring up the HTML panel on the right. As usual, hover over the highlighted part to confirm it's locked onto the correct element.
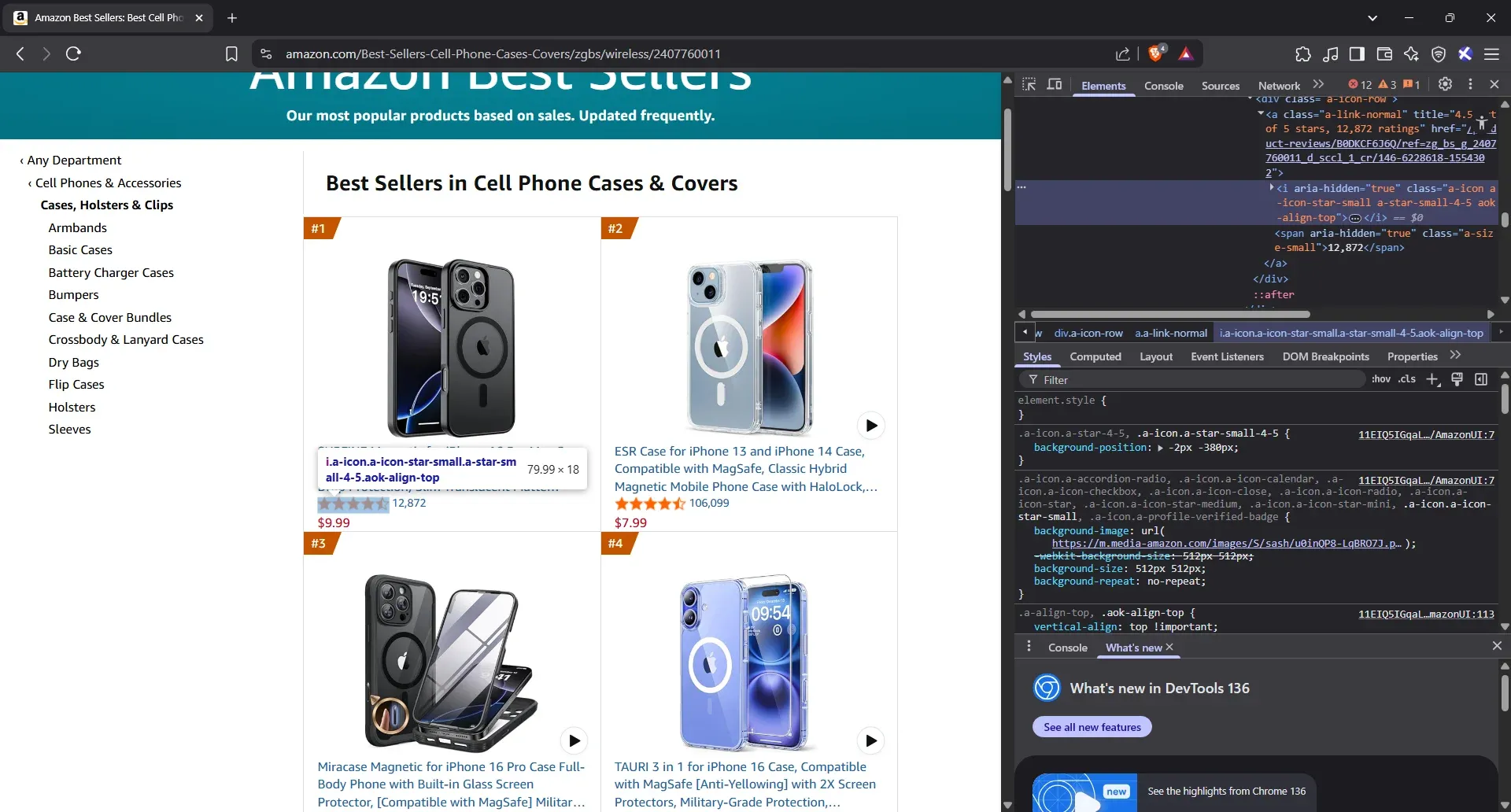
- Extract the star rating elements
That star icon is living inside an <i> tag. Take the full class string - don’t trim anything. No need for an attribute here. Just drop a-star-small-4-5 into the example column and move on.
- Inspect the number of reviews
Right next to the star icon, you’ll see the number of people who’ve left reviews. Click that number, choose Inspect, and let your browser show you the line of HTML it resides in. If you hover and the number highlights, you’ve got it.
- Extract the number of reviews attributes
The <span> tag holding the review count is already highlighted. Just copy the class, jot down the number you see, and you’re done with this row.
- Inspect the image URL
Click on the image itself, then Inspect. Once that <img> tag is highlighted, hover over it. If the picture on the page glows, you’ve landed exactly where you need to be.
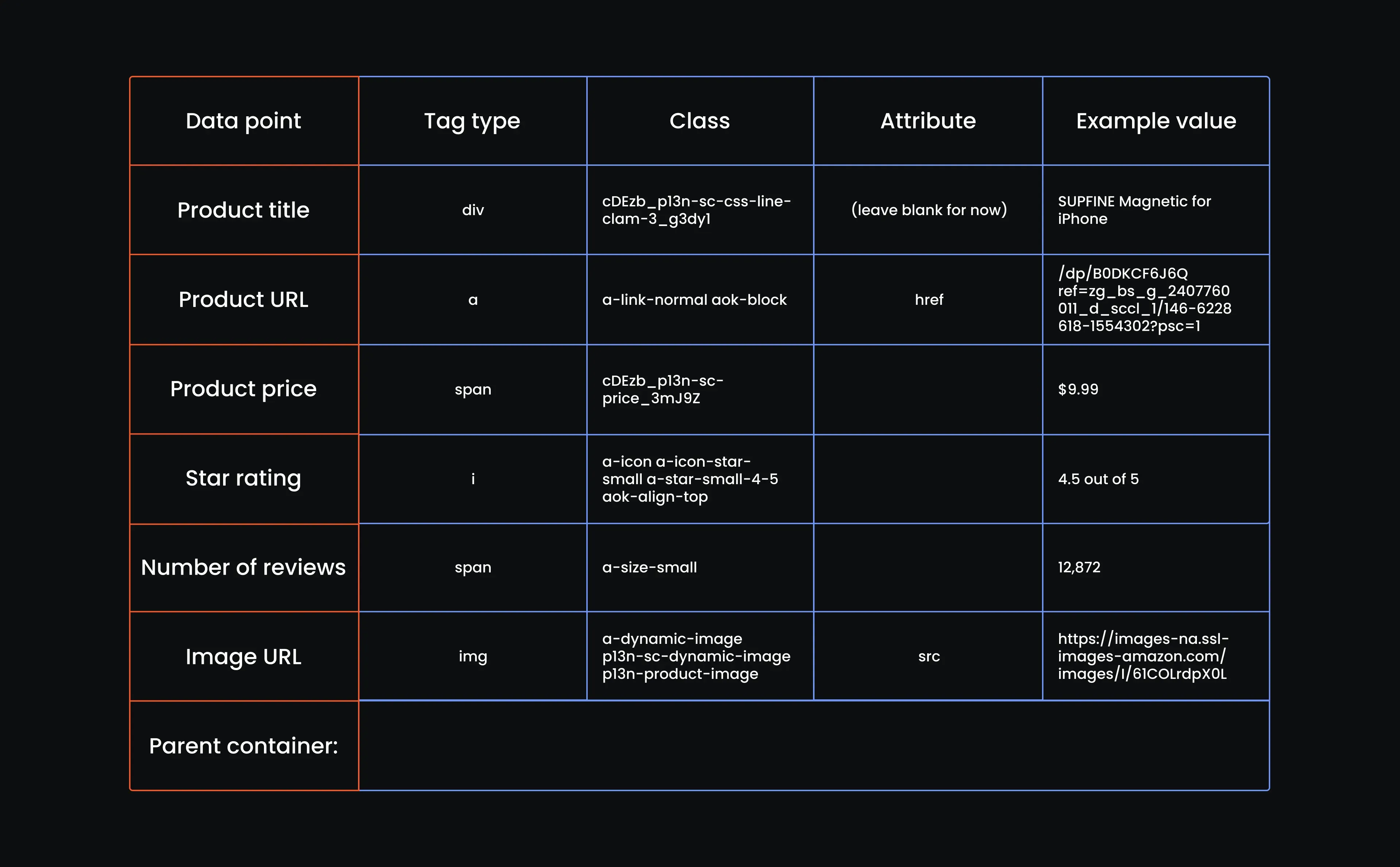
- Extract the image URL attributes
Once the image highlights as you hover, you’ve got your target. Just grab the img tag, copy the full class name exactly as it is, and pull the src attribute. That’s your product image.
- Find the parent container
We’re almost ready to scrape Amazon's best-selling phone cases page for real. There’s just one last thing you need to find. Trust us, this step will save you a great deal of pain later.
We’ve already identified the tags for the title, price, and other relevant details. But now we want to wrap it all up in one smart move: by locating the container that holds the entire product listing.
Here’s how you do it: go back to the Amazon Best Sellers page, pick any product (it doesn’t matter which), and click ‘Inspect’. You’ll see the HTML pop up on the side. Now. start hovering upward through the code. You’ll see pieces of the listing highlighted, like the title, the image, and the price.
Keep going until the entire card lights up. That’s your parent container. If you hover one level higher and suddenly other listings get included, you’ve gone too far. Back up one, and boom, that’s the target element you’ll use to anchor all your scraping logic.
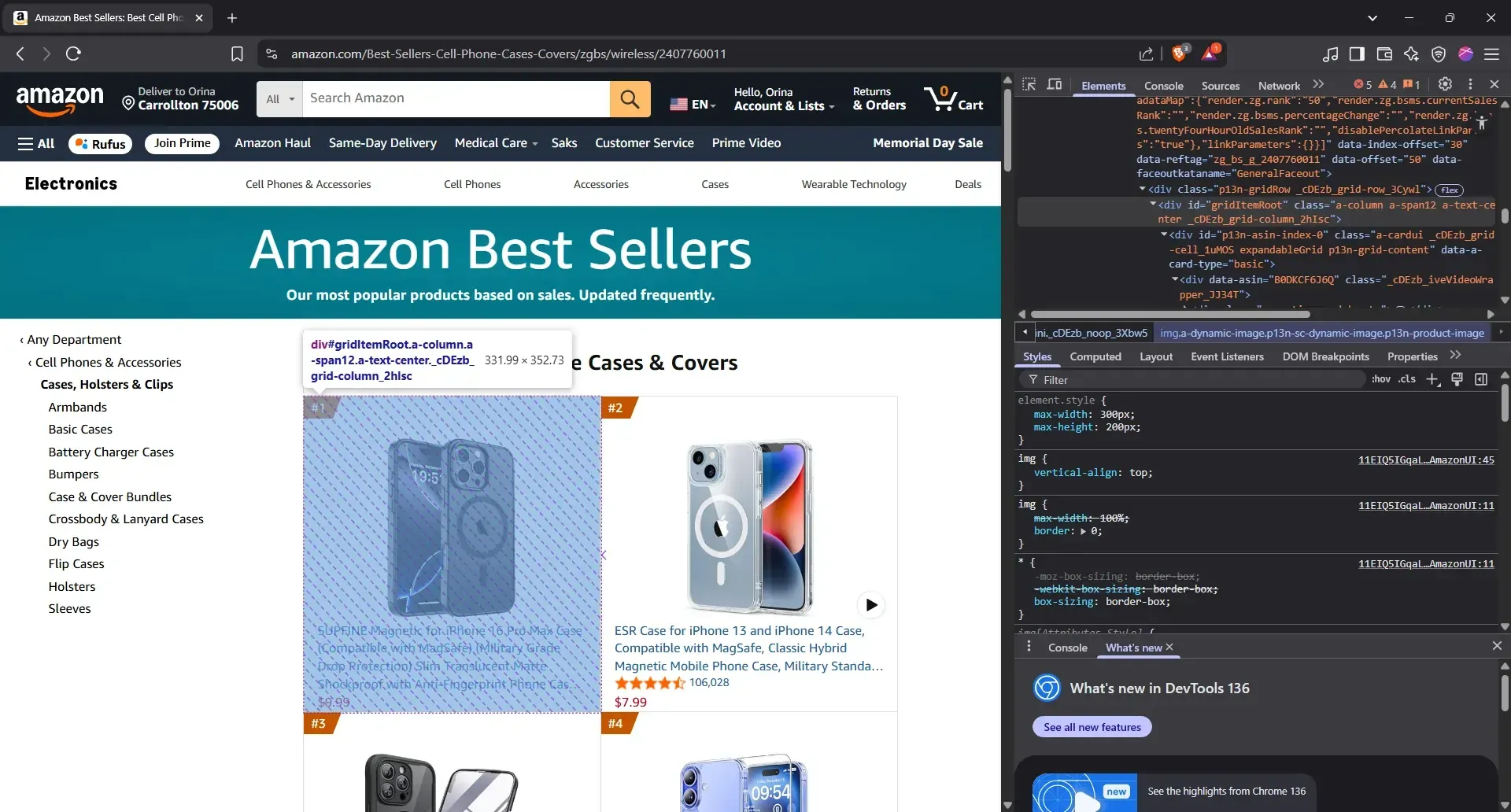
- Extract the parent container
<div class="zg-grid-general-faceout">
Now we can fill in our table:
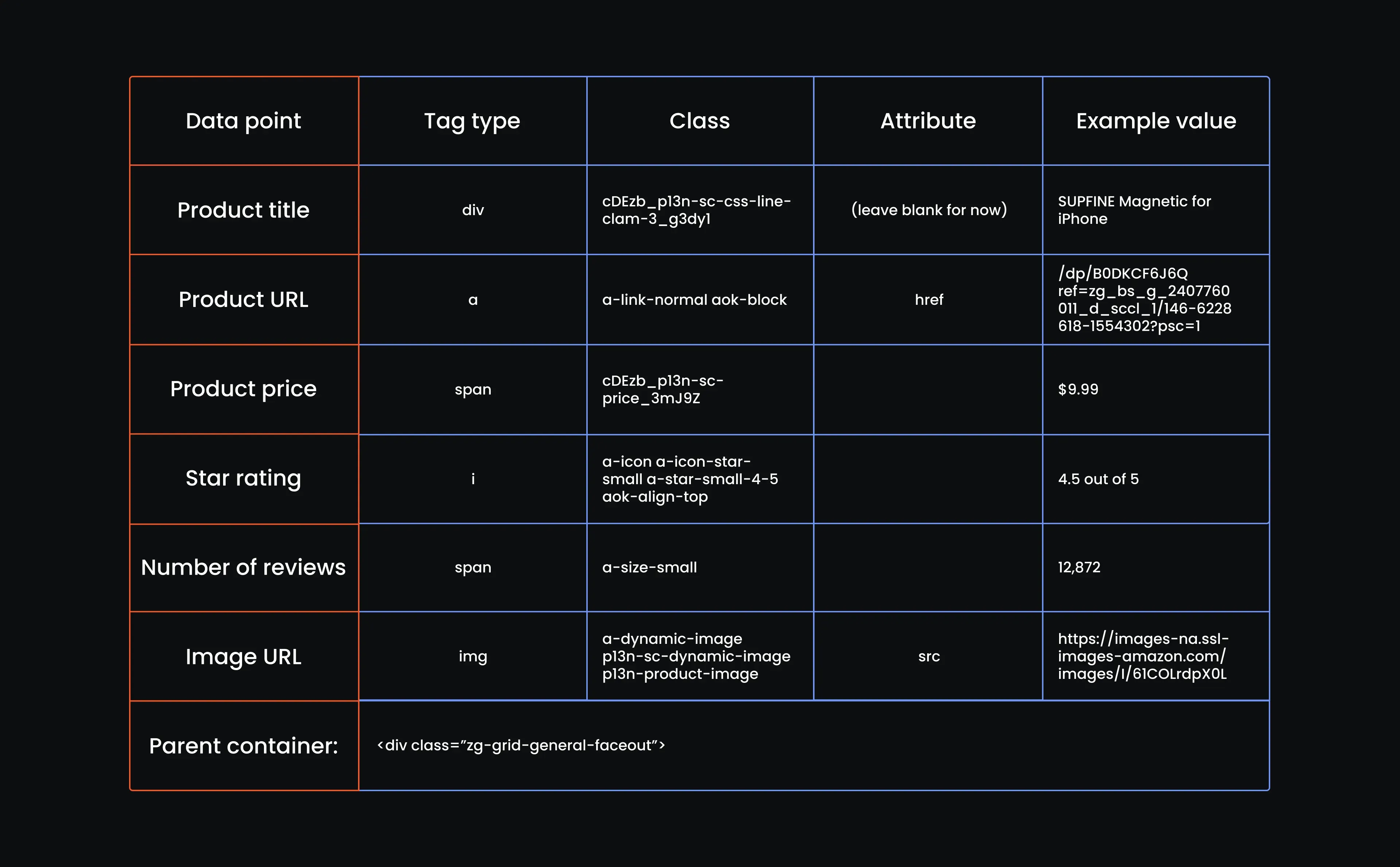
All right, we’ve mapped out the elements, scoped their tags, and built our reference table. Next up? Turning all that into code that actually scrapes Amazon data line by line.
Step 6: Defining our headers
Remember that long request loop we built earlier? It’s the foundation on which everything else stands. Each retry is a new attempt to bypass Amazon’s defenses. That’s why we ensured it rotates user agents, changes proxies, and waits random intervals. Now, we’re giving it one more advantage: smart, dynamic headers.
Headers are like the introduction you make when you arrive at a website. They tell Amazon what browser you're using, how you're connecting, and what page you came from. If those don’t change with every request, Amazon catches on. So, we place our headers inside the retry loop, the same one that changes user agents and proxies, so each request appears as a completely different visitor.
Update the script to this (mind the indentation):
while retries > 0 and not success:
user_agent = ua.random
proxies = random.choice(proxy_pool)
#Add your headers at this point
headers = {
"User-Agent": user_agent,
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Cache-Control": "no-cache",
"Referer": random.choice([
"https://www.google.com/",
"https://www.bing.com/",
"https://duckduckgo.com/"
]),
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Sec-Ch-Ua": '"Chromium";v="118", "Not=A?Brand";v="99", "Google Chrome";v="118"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"'
}
Let’s break this header down, line by line, so you know exactly what each part is doing and why it matters:
- User-Agent is the browser ID we randomized earlier.
- Accept-Language tells Amazon your preferred language. Real browsers include this, so we should, too.
- Accept-Encoding says what compression formats your browser can handle. It also affects how fast content loads.
- Accept defines the types of content your script is okay to receive. Think of it as your menu of options.
- Connection is set to keep-alive to mimic how real browsers maintain an open line instead of reconnecting on every request.
- Upgrade-Insecure-Requests tells Amazon you’re okay with HTTPS.
- Cache-Control tells Amazon we want the fresh page.
- Referrer pretends we came from Google, Bing, or DuckDuckGo.
- Sec-... are headers that basically describe the context of our request.
Now, we need to add this code block to our script. Here it is:
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import csv
import random
import time
print("Environment is ready. Scraping started.")
ua = UserAgent()
# Proxy pool with 5 full proxy entries (each includes http and https)
proxy_pool = [
{
"http": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-us_state-connecticut_session-i2dot8ln_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-us_state-connecticut_session-i2dot8ln_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-gb_city-auckley_session-bcvhavyg_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-gb_city-auckley_session-bcvhavyg_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-za_city-bloemfontein_session-cs66ctv9_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-za_city-bloemfontein_session-cs66ctv9_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-fr_city-avignon_session-tj4zlg8g_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-fr_city-avignon_session-tj4zlg8g_lifetime-20m@ultra.marsproxies.com:44443"
}
]
#Your request logic
session = requests.Session()
retries = 3
delay = 10
success = False
#Main request retry logic
while retries > 0 and not success:
user_agent = ua.random
proxies = random.choice(proxy_pool)
#Add your headers here
headers = {
"User-Agent": user_agent,
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Cache-Control": "no-cache",
"Referer": random.choice([
"https://www.google.com/",
"https://www.bing.com/",
"https://duckduckgo.com/"
]),
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Sec-Ch-Ua": '"Chromium";v="118", "Not=A?Brand";v="99", "Google Chrome";v="118"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"'
}
#Previous code continues
print(f"Trying with User-Agent: {user_agent}")
print(f"Using Proxy: {proxies['http']}")
time.sleep(random.uniform(3, 8))
try:
response = session.get(
"https://www.amazon.com/Best-Sellers-Cell-Phones-Accessories/zgbs/wireless/2407760011",
proxies=proxies,
timeout=20
)
print(f"Status Code: {response.status_code}")
# Parse the HTML response
soup = BeautifulSoup(response.content, "html.parser")
product_cards = soup.find_all("div", attrs={"data-asin": True})
# Block detection logic — now enhanced with parsing checks
if ("captcha" in response.url or
"[email protected]" in response.text or
soup.find("form", action="/errors/validateCaptcha") or
response.status_code != 200 or
len(product_cards) == 0):
print("Blocked or failed. Retrying...")
retries -= 1
time.sleep(delay)
delay *= 2
continue
# If we got here, we passed Amazon’s outer wall
print("Success! Got a response that wasn’t blocked.")
success = True
#Catch errors and retry with exponential backoff
except Exception as e:
print(f"Request failed: {e}. Retrying after {delay} seconds...")
time.sleep(delay)
retries -= 1
delay *= 2
Step 7: Extract phone case product data from the parsed HTML
So far, everything we’ve written is leading up to this one core idea: don’t move forward until you’re sure Amazon actually gave you something real. Here’s what has to line up before we even think about extracting data:
- You’ve made the request successfully
- The response isn’t a CAPTCHA page
- The status code is 200
- There’s no fallback support email in the response
- product_cards actually contains elements (i.e., len(product_cards) > 0)
Only when all of that checks out do we let the scraper walk through the front door and start gathering data. That’s why the product extraction loop doesn’t go at the bottom of the script or outside the retry block. It lives right here, right after this line:
# If we got here, we passed Amazon’s outer wall
print("Success! Got a response that wasn’t blocked.")
success = True
#Your product extraction loop starts here
if response.status_code == 200 and len(product_cards) > 0:
This condition ensures that Amazon responds with a legitimate page (not a CAPTCHA or a decoy) and that we’ve got actual product blocks sitting in the soup. Only then do we move forward with parsing titles, prices, ratings, and all the data we came for. Now we can start building our data extraction code block:
- Loop through each product card
Let’s start looping through product_cards to extract individual details. Write this script:
# If we got here, we passed Amazon’s outer wall
print("Success! Got a response that wasn’t blocked.")
success = True
#Your product extraction loop starts here
if response.status_code == 200 and len(product_cards) > 0:
#Start looping through each product card
for idx, card in enumerate(product_cards, start=1):
This begins looping through each product container you previously located with find_all.
- Extract the title
Return to your reference table and examine the first row. The one that says:
Tag type: div, class: cDEzb_p13n-sc-css-line-clamp-3_g3dy1
Here’s how you turn that into something your Python file understands:
title_tag = card.find("div", class_=lambda c: c and "line-clamp" in c)
product_title = title_tag.get_text(strip=True) if title_tag else None
Now, you might be wondering, why not just plug in the full class string from our reference table? Amazon’s front-end code changes like the wind. Class names get regenerated, obfuscated, even split up. But the keyword "line-clamp" sticks around. So, instead of relying on fragile exact matches, we opt for flexibility. The lambda c: bit is just saying: “Hey, if the class exists and includes ‘line-clamp,’ grab it.”
- Extract the URL
Now, we’re moving to the second row in your reference table: the phone case URL.
You’re looking for:
- Tag: a
- Class: a-link-normal aok-block
- Attribute: href
Now, let’s translate that into Python:
link_tag = card.find("a", class_="a-link-normal aok-block")
product_url = f"https://www.amazon.com{link_tag['href']}" if link_tag and 'href' in link_tag.attrs else None
Let’s break this down:
- We’re telling BeautifulSoup, “Find the <a> tag with this class, but just inside this card.”
- Then we check: does it actually have a href attribute?
- If yes, great. We add https://www.amazon.com to the front and call it a day
- If not, we return None, and our script stays calm and continues
- Extract the product price
Next on the checklist is the product price. Back to the table, third row down.
You’re looking at:
- Tag: span
- Class: cDEzb_p13n-sc-price_3mJ9Z
Let’s write it in code:
price_tag = card.find("span", class_=lambda c: c and "price" in c)
product_price = price_tag.get_text(strip=True) if price_tag else None
Here is what all that means:
- .find() targets just one tag, the first one that matches
- .get_text(strip=True) pulls the price without the weird gaps or line breaks
- If the price isn’t found (because maybe it’s a sponsored listing or something unusual), the else None keeps your script from faceplanting
- Extract the star rating
From our table:
- Tag: i
- Class: a-icon a-icon-star-small a-star-small-4-5 aok-align-top
Here’s the code:
star_tag = card.find("i", class_=lambda c: c and "star" in c)
star_rating = star_tag.get_text(strip=True) if star_tag else None
Here’s what this does:
- .find() looks for that <i> tag inside the current product block
- .get_text(strip=True) pulls the actual star rating and removes any extra whitespace
- The if ... else None bit makes sure your script doesn’t throw a fit if the rating isn’t there, it just moves on
- Extract the number of reviews
Let’s get the number of reviews. It’s row five on your reference table. What you’re targeting is a simple <span> with the class a-size-small. You don’t need to mess with attributes for this one.
Now let us translate this into code:
reviews_tag = card.find("span", class_="a-size-small")
number_of_reviews = reviews_tag.get_text(strip=True) if reviews_tag else None
Here’s what’s happening:
- find() searches inside each product card for that exact <span> class
- get_text(strip=True) pulls the review count and removes any extra whitespace or weird line breaks
- The if ... else None is just a backup. It keeps your script from crashing if one of the cards doesn’t have reviews
- Extract the image URL
You’re looking at the sixth row now:
- Tag: img
- Class: a-dynamic-image p13n-sc-dynamic-image p13n-product-image
- Attribute: src
Here’s your code:
image_tag = card.find("img", class_=lambda c: c and "image" in c)
image_url = image_tag["src"] if image_tag and "src" in image_tag.attrs else None
Here is what this means:
- .find() narrows the search to the exact image tag inside each product listing
- ["src"] goes straight to the image URL
- if image_tag else None keeps your Python file smooth and crash-free
- Store all extracted values
We’ve pulled everything. Now, let’s bundle that all up. Still inside your loop, add this line:
product_data = [product_title, product_url, product_price, star_rating, number_of_reviews, image_url]
Here’s what’s happening:
- You’re grouping everything you just scraped for this product
- Each value sits in the same order every time, so it’s easy to write to your CSV later
- And if something's missing (maybe a product doesn’t show a rating), the None you assigned earlier holds that spot
- Full code block
We are now done with the logic for extracting data. Here is the full code block:
# If we got here, we passed Amazon’s outer wall
print("Success! Got a response that wasn’t blocked.")
success = True
# Your product extraction loop starts here
if response.status_code == 200 and len(product_cards) > 0:
for idx, card in enumerate(product_cards, start=1):
title_tag = card.find("div", class_=lambda c: c and "line-clamp" in c)
product_title = title_tag.get_text(strip=True) if title_tag else None
link_tag = card.find("a", class_="a-link-normal aok-block")
product_url = f"https://www.amazon.com{link_tag['href']}" if link_tag and 'href' in link_tag.attrs else None
price_tag = card.find("span", class_=lambda c: c and "price" in c)
product_price = price_tag.get_text(strip=True) if price_tag else None
star_tag = card.find("i", class_=lambda c: c and "star" in c)
star_rating = star_tag.get_text(strip=True) if star_tag else None
reviews_tag = card.find("span", class_="a-size-small")
number_of_reviews = reviews_tag.get_text(strip=True) if reviews_tag else None
image_tag = card.find("img", class_=lambda c: c and "image" in c)
image_url = image_tag["src"] if image_tag and "src" in image_tag.attrs else None
product_data = [
product_title,
product_url,
product_price,
star_rating,
number_of_reviews,
image_url
]
print(f"Extracted product {idx}: {product_title[:50] if product_title else '[No Title]'}")
Let's recap and look at our code up to this point:
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import random
import time
print("Environment is ready. Scraping started.")
# Setup user agent generator
ua = UserAgent()
# Proxy pool with 5 full proxy entries (each includes http and https)
proxy_pool = [
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
},
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
},
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
},
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
},
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
}
]
#Your request logic starts here
session = requests.Session()
retries = 3
delay = 10
success = False
# Main request retry logic
while retries > 0 and not success:
user_agent = ua.random
proxies = random.choice(proxy_pool)
#Youur headers ggo here
headers = {
"User-Agent": user_agent,
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Cache-Control": "no-cache",
"Referer": random.choice([
"https://www.google.com/",
"https://www.bing.com/",
"https://duckduckgo.com/"
]),
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Sec-Ch-Ua": '"Chromium";v="118", "Not=A?Brand";v="99", "Google Chrome";v="118"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"'
}
#Rest of the code continues
print(f"Trying with User-Agent: {user_agent}")
print(f"Using Proxy: {proxies['http']}")
time.sleep(random.uniform(3, 8))
#The main GETrequest
try:
response = session.get(
"https://www.amazon.com/Best-Sellers-Cell-Phones-Accessories/zgbs/wireless/2407760011",
headers=headers,
proxies=proxies,
timeout=20
)
print(f"Status Code: {response.status_code}")
#Parse Amazon's response and look for the main product container
soup = BeautifulSoup(response.content, "html.parser")
product_cards = soup.find_all("div", attrs={"data-asin": True})
#Check for errors in the parsed response
if ("captcha" in response.url or
"[email protected]" in response.text or
soup.find("form", action="/errors/validateCaptcha") or
response.status_code != 200 or
len(product_cards) == 0):
print("Blocked or failed. Retrying...")
retries -= 1
time.sleep(delay)
delay *= 2
continue
print("Success! Got a response that wasn’t blocked.")
success = True
#Start extracting data from each product card
#If response is Ok, parse the the product data
for idx, card in enumerate(product_cards, start=1):
title_tag = card.find("div", class_=lambda c: c and "line-clamp" in c)
product_title = title_tag.get_text(strip=True) if title_tag else None
link_tag = card.find("a", class_="a-link-normal aok-block")
product_url = f"https://www.amazon.com{link_tag['href']}" if link_tag and 'href' in link_tag.attrs else None
price_tag = card.find("span", class_=lambda c: c and "price" in c)
product_price = price_tag.get_text(strip=True) if price_tag else None
star_tag = card.find("i", class_=lambda c: c and "star" in c)
star_rating = star_tag.get_text(strip=True) if star_tag else None
reviews_tag = card.find("span", class_="a-size-small")
number_of_reviews = reviews_tag.get_text(strip=True) if reviews_tag else None
image_tag = card.find("img", class_=lambda c: c and "image" in c)
image_url = image_tag["src"] if image_tag and "src" in image_tag.attrs else None
product_data = [product_title, product_url, product_price, star_rating, number_of_reviews, image_url]
print(f"Product {idx}: {product_data}")
#If request response has errors, stop and retry
except Exception as e:
print(f"Request failed: {e}. Retrying after {delay} seconds...")
time.sleep(delay)
retries -= 1
delay *= 2
So far, we’ve built a web scraping script that fetches the first batch of Amazon product information and parses it. Great start. But that’s just one round. One page. A single snapshot in what could be a full-blown dataset.
We want to go deeper. We want pagination, and we want every bit of scraped data saved to a CSV file as we go. These next parts will turn our scraper into a proper tool. One that extracts product details from multiple Amazon phone case best seller pages and quietly logs it all in a file you can use later.
So let’s do that. First, let's add pagination logic.
Step 8: Adding pagination logic
Every Amazon phone case best seller's page shows around 30 products. We want 60, so we’re scraping pages 1 and 2. However, what a lot of people overlook is that page 2 is just as protected as page 1. Sometimes even more. That’s why the pagination logic doesn’t go at the end.
Instead, it wraps around the entire retry block. Each time we load a page, we want to treat it as its own self-contained scraping mission. So this is where you place it:
#Start of your request logic
session = requests.Session()
# Paginate through first two pages
for page in range(1, 3): # Scrape pages 1 to 2
retries = 3
delay = 10
success = False
#Same code continues
while retries > 0 and not success:
If page 1 fails, we retry page 1. If page 2 fails, we retry page 2. Simple, clear, and far more reliable when scraping Amazon product data.
You'll also want to add this block right after where you defined headers:
url =
f"https://www.amazon.com/Best-Sellers-Cell-Phones-Accessories/zgbs/wireless/2407760011?pg={page}"
print(f"\nScraping Page {page}")
print(f"Trying with User-Agent: {user_agent}")
print(f"Using Proxy: {proxies['http']}")
Since we’re paginating through Amazon’s Best Sellers, we need to update the URL on every loop to reflect which page we’re requesting. That’s exactly what url = f"...?pg={page}" does. It dynamically plugs in the current page number from the pagination loop.
We also log the page number, the selected identity string, and the proxy being used. These print statements make debugging a lot easier, especially when things break, or you’re trying to track patterns in failed requests.
So, place this block right after the headers and before sending the GET request; it’s how each iteration of your scraping loop knows what page it’s supposed to grab.
Here is the script with pagination logic added:
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import random
import time
print("Environment is ready. Scraping started.")
# Setup user agent generator
ua = UserAgent()
# Proxy pool with 5 full proxy entries (each includes http and https)
proxy_pool = [
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
},
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
},
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
},
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
},
{
"http": "http://user:[email protected]:44443",
"https": "http://user:[email protected]:44443"
}
]
session = requests.Session()
# Paginate through first two pages
for page in range(1, 3): # Scrape pages 1 to 2
retries = 3
delay = 10
success = False
while retries > 0 and not success:
user_agent = ua.random
proxies = random.choice(proxy_pool)
headers = {
"User-Agent": user_agent,
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Cache-Control": "no-cache",
"Referer": random.choice([
"https://www.google.com/",
"https://www.bing.com/",
"https://duckduckgo.com/"
]),
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Sec-Ch-Ua": '"Chromium";v="118", "Not=A?Brand";v="99", "Google Chrome";v="118"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"'
}
#Print current page being scraped in the pagination loop
url = f"https://www.amazon.com/Best-Sellers-Cell-Phones-Accessories/zgbs/wireless/2407760011?pg={page}"
print(f"\nScraping Page {page}")
print(f"Trying with User-Agent: {user_agent}")
print(f"Using Proxy: {proxies['http']}")
time.sleep(random.uniform(3, 8))
try:
response = session.get(
url,
headers=headers,
proxies=proxies,
timeout=20
)
print(f"Status Code: {response.status_code}")
soup = BeautifulSoup(response.content, "html.parser")
product_cards = soup.find_all("div", attrs={"data-asin": True})
if ("captcha" in response.url or
"[email protected]" in response.text or
soup.find("form", action="/errors/validateCaptcha") or
response.status_code != 200 or
len(product_cards) == 0):
print("Blocked or failed. Retrying...")
retries -= 1
time.sleep(delay)
delay *= 2
continue
print("Success! Got a response that wasn’t blocked.")
success = True
#Start of the data extraction loop
if response.status_code == 200 and len(product_cards) > 0:
for idx, card in enumerate(product_cards, start=1):
title_tag = card.find("div", class_=lambda c: c and "line-clamp" in c)
product_title = title_tag.get_text(strip=True) if title_tag else None
link_tag = card.find("a", class_="a-link-normal aok-block")
product_url = f"https://www.amazon.com{link_tag['href']}" if link_tag and 'href' in link_tag.attrs else None
price_tag = card.find("span", class_=lambda c: c and "price" in c)
product_price = price_tag.get_text(strip=True) if price_tag else None
star_tag = card.find("i", class_=lambda c: c and "star" in c)
star_rating = star_tag.get_text(strip=True) if star_tag else None
reviews_tag = card.find("span", class_="a-size-small")
number_of_reviews = reviews_tag.get_text(strip=True) if reviews_tag else None
image_tag = card.find("img", class_=lambda c: c and "image" in c)
image_url = image_tag["src"] if image_tag and "src" in image_tag.attrs else None
product_data = [product_title, product_url, product_price, star_rating, number_of_reviews, image_url]
print(f"Product {idx}: {product_data}")
#Catch errors and retry with exponential backoff
except Exception as e:
print(f"Request failed: {e}. Retrying after {delay} seconds...")
time.sleep(delay)
retries -= 1
delay *= 2
Step 9: Saving parsed data to a CSV file
It’s time to write to a CSV file. But we don’t want to open and close a file with every page, every retry, or every proxy swap. That’s a fast way to get errors or lose data. Instead, we open the CSV once at the very beginning and wrap all our scraping logic inside it. That way, everything lives neatly inside one writing session.
So add this code at the beginning of your request script:
# CSV setup
csv_path = "amazon_products.csv"
with open("amazon_products.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["Title", "URL", "Price", "Rating", "Reviews", "Image"])
# the code above opens the CSV file before you send the requests
session = requests.Session()
for page in range(1, 3): # Scrape pages 1 to 2
retries = 3
delay = 10
success = False
while retries > 0 and not success:
#same code continues
- csv_path = "amazon_products.csv" stores the name of the CSV file as a variable (csv_path)
- with open(...) as file opens your CSV once and automatically closes it when you’re done
- writer.writerow([...]) writes your header row, so your CSV isn’t just a wall of data with no labels
We perform all our Amazon scraping within the with block, which means every product is written to the file as soon as it's scraped.
Step 10: Full code
And now, your final script, ready to scrape data from Amazon:
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import csv
import random
import time
print("Environment is ready. Let’s scrape something.")
ua = UserAgent()
# Proxy pool with 5 full proxy entries (each includes http and https)
proxy_pool = [
{
"http": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-no_city-oslo_session-sojrcs6x_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-us_state-connecticut_session-i2dot8ln_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-us_state-connecticut_session-i2dot8ln_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-gb_city-auckley_session-bcvhavyg_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-gb_city-auckley_session-bcvhavyg_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-za_city-bloemfontein_session-cs66ctv9_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-za_city-bloemfontein_session-cs66ctv9_lifetime-20m@ultra.marsproxies.com:44443"
},
{
"http": "http://random:MKRYlpZgSa_country-fr_city-avignon_session-tj4zlg8g_lifetime-20m@ultra.marsproxies.com:44443",
"https": "http://random:MKRYlpZgSa_country-fr_city-avignon_session-tj4zlg8g_lifetime-20m@ultra.marsproxies.com:44443"
}
]
# CSV setup
csv_path = "amazon_products.csv"
#Opening the CSV file and writing the header row
with open(csv_path, mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["Title", "URL", "Price", "Rating", "Reviews", "Image"])
#Start of your request logic
session = requests.Session()
#Start of your pagination logic
for page in range(1, 3): # Scrape pages 1 to 2
retries = 3
delay = 10
success = False
# Main request retry logic
while retries > 0 and not success:
user_agent = ua.random
proxies = random.choice(proxy_pool)
# Insert your headers
headers = {
"User-Agent": user_agent,
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Cache-Control": "no-cache",
"Referer": random.choice([
"https://www.google.com/",
"https://www.bing.com/",
"https://duckduckgo.com/"
]),
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Sec-Ch-Ua": '"Chromium";v="118", "Not=A?Brand";v="99", "Google Chrome";v="118"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"'
}
#Printing the page currently being scraped along with the user agent and proxy in use
url = f"https://www.amazon.com/Best-Sellers-Cell-Phones-Accessories/zgbs/wireless/2407760011?pg={page}"
print(f"\nScraping Page {page}")
print(f"Trying with User-Agent: {user_agent}")
print(f"Using Proxy: {proxies['http']}")
#Natural pause
time.sleep(random.uniform(3, 8))
# Sending your GET request
try:
response = session.get(url, headers=headers, proxies=proxies, timeout=20)
print(f"Status Code: {response.status_code}")
#Parsing the response and locating the product container
soup = BeautifulSoup(response.content, "html.parser")
product_cards = soup.find_all("div", attrs={"data-asin": True})
#Checking for errors in the parsed Amazon response
if ("captcha" in response.url or
"[email protected]" in response.text or
soup.find("form", action="/errors/validateCaptcha") or
response.status_code != 200 or
len(product_cards) == 0):
print("Blocked or failed. Retrying...")
retries -= 1
time.sleep(delay)
delay *= 2
continue
if response.status_code == 200 and len(product_cards) > 0:
success = True
for idx, card in enumerate(product_cards, start=1):
title_tag = card.find("div", class_=lambda c: c and "line-clamp" in c)
product_title = title_tag.get_text(strip=True) if title_tag else None
link_tag = card.find("a", class_="a-link-normal aok-block")
product_url = f"https://www.amazon.com{link_tag['href']}" if link_tag and 'href' in link_tag.attrs else None
price_tag = card.find("span", class_=lambda c: c and "price" in c)
product_price = price_tag.get_text(strip=True) if price_tag else None
star_tag = card.find("i", class_=lambda c: c and "star" in c)
star_rating = star_tag.get_text(strip=True) if star_tag else None
reviews_tag = card.find("span", class_="a-size-small")
number_of_reviews = reviews_tag.get_text(strip=True) if reviews_tag else None
image_tag = card.find("img", class_=lambda c: c and "image" in c)
image_url = image_tag["src"] if image_tag and "src" in image_tag.attrs else None
product_data = [product_title, product_url, product_price, star_rating, number_of_reviews, image_url]
writer.writerow(product_data)
print(f"Wrote product {idx}: {product_title[:50] if product_title else '[No Title]'}")
else:
print(f"Retrying after {delay} seconds...")
time.sleep(delay)
retries -= 1
delay *= 2
except Exception as e:
print(f"Error: {e}. Retrying after {delay} seconds...")
time.sleep(delay)
retries -= 1
delay *= 2
print("Scraping complete. Data saved to amazon_products.csv")
Step 11: Running your finished Amazon scraper
You’ve got the code. You’ve got the proxies. You’ve got the logic in place. Now it’s time to see what it actually returns. Head back to your terminal, make sure you're still inside the folder where you saved the script, and type:
python final_amazon_scraper.py
Then press Enter and wait. Don’t worry if it takes a little while. The scraper rotates user agents, switches proxies, checks for CAPTCHAs, and slowly works its way through each Amazon page. Give it a moment.
Is it done? Let’s make sense of our output.
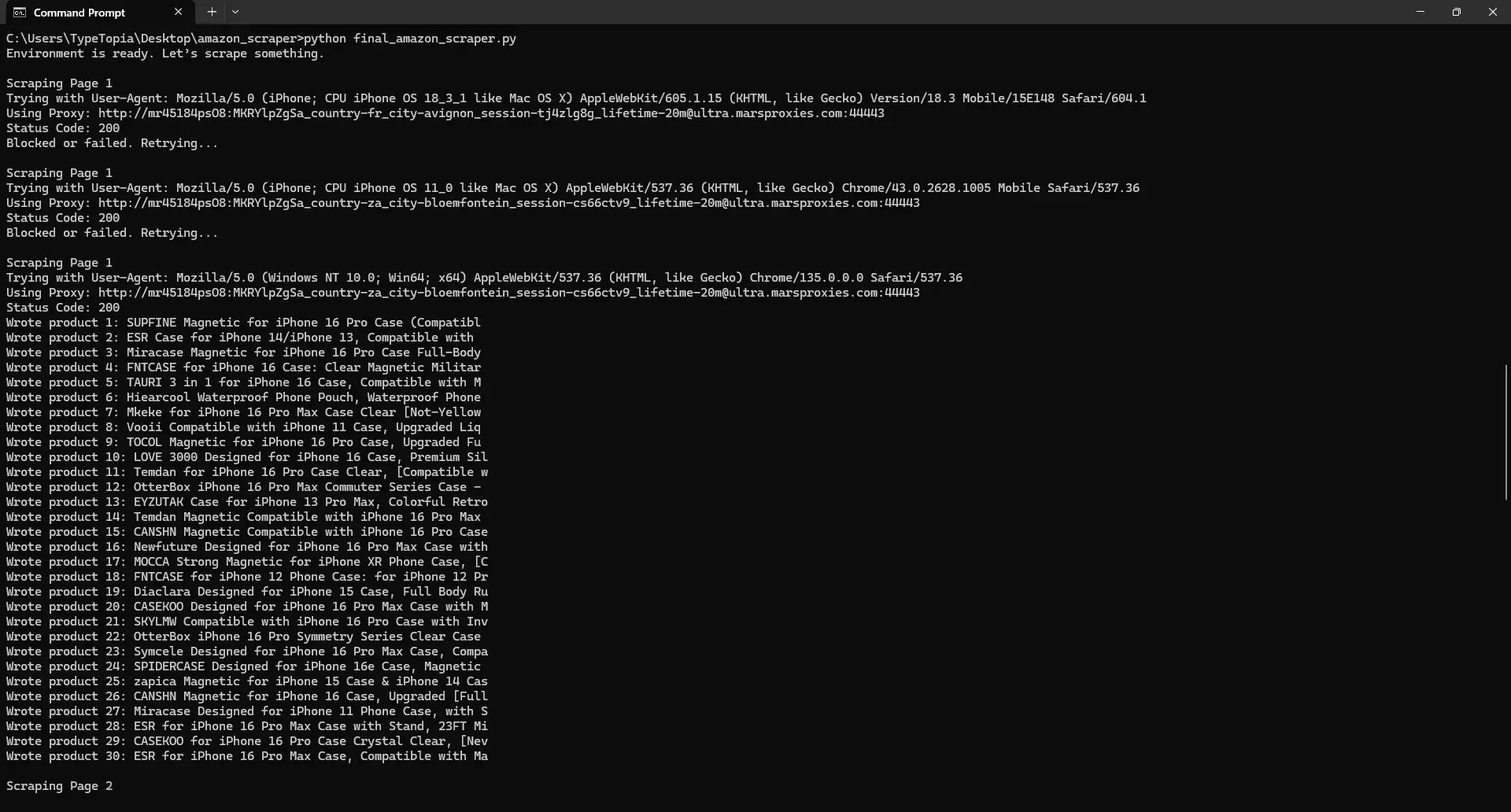
Take a look at that first screenshot. Everything kicked off the way it should. Then, your Amazon scraper fired its first shot at page 1. Amazon responded with a 200 OK, which might look like success… but it wasn’t. What you actually got back was a decoy, a page with no real data, likely a CAPTCHA or placeholder HTML.
Thankfully, your block detection logic spotted the issue right away. No wasted parsing. It backed off, waited 10 seconds, switched to a new IP address, a fresh user agent, and new headers, then tried again.
The second attempt? Same story. Another fake page. But on the third go, everything finally lined up. Your script pierced Amazon’s outer defenses, identified real product containers, and extracted all 30 items from the page. You even see each product logged as it’s written to your CSV file. That’s a resilient scraper.
Thanks to the pagination loop, we moved on to scrape page 2.
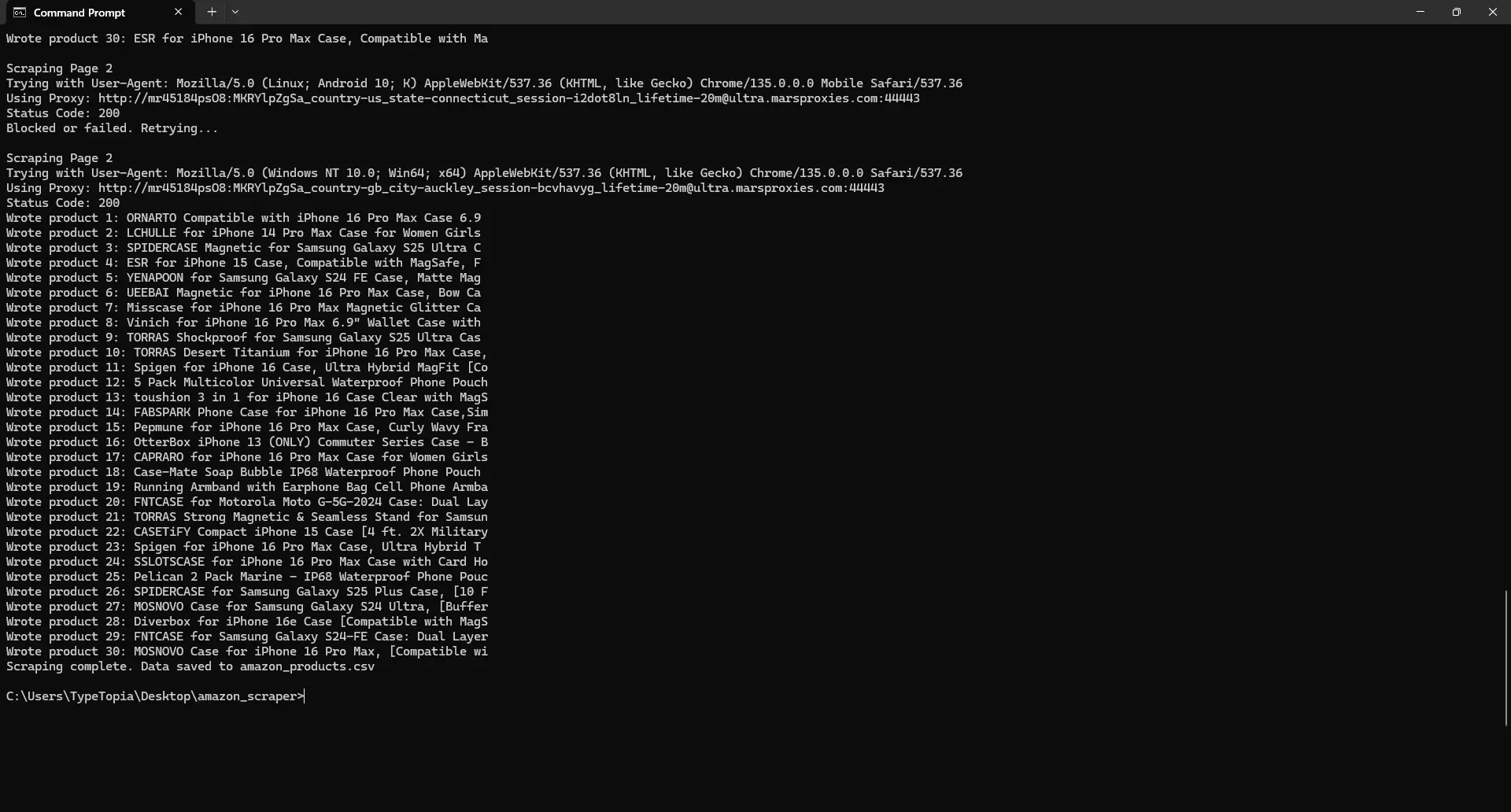
Amazon gave us another polite 200, but behind the curtain? Likely nothing useful. Maybe placeholder HTML. Maybe a CAPTCHA wall. Either way, we knew what to do. The script paused, dressed up again with a new proxy and user agent, and knocked a second time.
That’s when it worked. Just like on page 1, it located the actual product containers and began printing each item, 30 more in total. And with that, the full round of Amazon product data was safely logged. That’s a win.
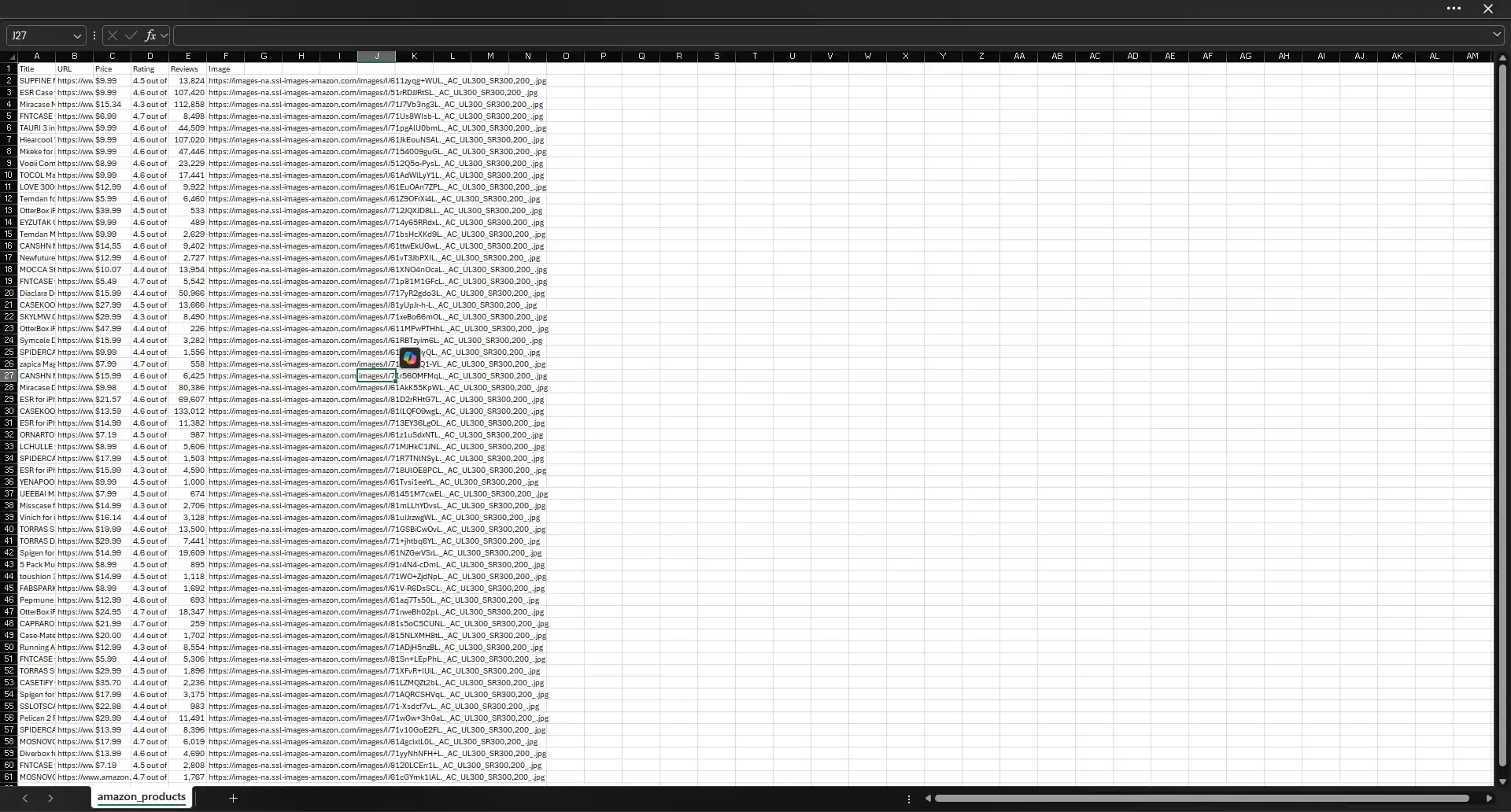
But was the data saved to the CSV file?
Let’s check. Navigate to the amazon_scraper folder and locate the CSV file named amazon_products.csv. If everything went right, it should be populated with 60 products with rows listing the title, URL, price, rating, reviews, and image URL. Here's ours:
Common challenges in Amazon scraping
If you thought a basic requests.get() would get you to the product listings, this script probably changed your mind. You’ve seen it for yourself: blocks, CAPTCHAs, and fake pages that look real but aren’t.
Amazon’s defenses are built to keep bots out, and that includes our script. The only way to survive is to anticipate its checks, rotate your identity, and act human. Because the default scraping playbook just won’t cut it here.
Below are the challenges that our scraping process anticipated and addressed:
Incorrect/empty data
Here’s something that might have felt weird the first time you saw it: why are we checking for len(product_cards) > 0 after receiving a 200 OK from Amazon? Shouldn’t 200 mean everything worked?
Technically, yes. However, in Amazon scraping, it just means something returned. And that something might not necessarily be what you wanted. That’s intentional.
Amazon knows that returning a hard error like 403 or 429 is too helpful. You’d just tweak your code, retry with a different user agent, or rotate your IP. Instead, it hits you with a “fake success.” The HTML looks real, but it’s empty. Or worse, it has a CAPTCHA hidden inside a div that resembles your target page. Other times, that 200 might be a stripped-down mobile page.
So we don’t just check for a valid response - we validate whether it contains product data. Because if it doesn’t, we back off and try again.
It’s like unlocking what looks like your apartment door, walking in, and realizing nothing inside is yours. Same floor, same number, but everything’s off. The lights work, sure. But the furniture’s staged, and there’s no fridge. Amazon’s fake responses are just like that: they feel real enough to fool a bot but not enough to deliver anything useful to us humans.
IP blocking and rate limiting
The other thing you’ve probably noticed is that we never rush Amazon. Not once. Every time our script gets blocked, it doesn’t just panic and fire off another request - it pauses. First for 10 seconds, then 20, then 40.
That’s a strategic way to avoid rate limiting, where Amazon punishes you for making too many requests too fast.
Best practices & tips
As you’ve seen from our script, scraping Amazon is more about strategy than brute force, and that means embracing a few key best practices.
Scrape from category pages instead of search
Search pages are Amazon’s tightest gate. They come with unpredictable layouts, heavy scripting, and layered defenses that make scraping a headache.
Category pages, on the other hand, like Best Sellers or niche product lists, follow a more predictable structure. You still have to dodge fake pages and CAPTCHAs, but your odds are better. Think of them as the slightly more forgiving cousins of the search results page.
Rotate proxies and real user agents
The easiest way to get yourself blocked is to show up twice in the same outfit. Amazon tracks patterns, and repeating IPs or user agent strings is one of the quickest ways to get shut out. That’s why our scraper switches both with every single request.
Throttle your request rate
Amazon watches how often you knock. Knock too often, too fast, and you’re out. We address this issue with two tactics: random delays between 3 and 8 seconds to simulate human browsing, and exponential backoff if we hit a wall. That’s 10 seconds on the first fail, then 20, then 40.
Best tools for Amazon data scraping
Python libraries
Let’s take a second to appreciate the small but mighty tools that made this script tick. These libraries did the heavy lifting:
- requests sent our GET requests, complete with headers and proxies.
- BeautifulSoup parsed the raw data (HTML) so we could identify and extract product titles, prices, images, and reviews.
- fake_useragent kept our identity fresh by switching up the user-agent strings every time.
- csv gave us a place to store the final data in spreadsheet form.
- random made sure our requests didn’t look robotic by adding a bit of unpredictability.
- time paused the script, working with random to simulate human-like behavior.
This article offers more insight on how to master Python web Scraping with tools, tips, and techniques.
Browser automation tools: Selenium and Playwright
If our script taught you anything, it’s that Amazon's anti-scraping measures fight back. Aggressively. To reduce the number of failsafes and sanity checks in your scraper, consider switching to headless browser tools like Selenium or Playwright. These are fully simulated browsers that can see exactly what a real user sees. That includes JavaScript-heavy content, popups, mobile views, and even CAPTCHA prompts.
This extra visibility lets you catch things requests can’t. Got served a blank page or a mobile layout missing data containers? Automation tools can detect that. Hit a CAPTCHA? Screenshot it, solve it (with a service or your own handler), and move on. You won’t eliminate all scraping challenges, but you’ll definitely spend less time writing workarounds for problems these tools can solve in one shot.
Proxy services: Residential vs. datacenter proxies
We deliberately chose residential proxies for this project because they blend in. These IPs are assigned to real users with real ISPs, meaning they reflect genuine residential traffic. That matters when you're scraping a platform as tightly guarded as Amazon. Every request that looks normal helps you stay off the radar a little longer.
Now, datacenter proxies can absolutely move quickly and scale big, but they’re a double-edged sword. Because they originate from cloud infrastructure and data farms, they leave a distinct fingerprint. Amazon knows this. It watches for those patterns and reacts fast.
So, while datacenter IPs may get you in the door, they also get you kicked out faster. Residential IPs, meanwhile, make you appear as if you belong. Read our guide for more information on how Mars Residential proxies fare in real world web scraping.
Ethical considerations and best practices
Here is how to extract data from Amazon responsibly:
- Respecting robots.txt and Terms of Service
Amazon’s robots.txt file restricts bots from scraping many of its pages, but ignoring that file isn’t illegal in most jurisdictions.
- Limiting request rates to avoid server overload
We built in delays and exponential backoffs to stay under the radar and avoid sending too many requests too fast. Amazon will usually block you before you crash anything, but still: don’t be the reason they tighten the screws on everyone else.
- Ensuring data privacy and compliance
Stick to publicly available data. Avoid anything that could reveal personal information about users.
Our article offers a deep dive into how to scrape data from any website, not just Amazon. If you're looking for general web scraping techniques, it's a great place to start.
Final words
If you’ve made it this far, you now know that Amazon isn’t impossible to scrape. It just doesn’t make things easy. And that’s okay. You don’t need easy - you need smart, strategic, and patient. The kind of scraping that adapts, retries, rotates, and checks twice before calling anything a win.
So here’s to you, and here’s to scraping sessions filled with real 200s, not the kind that smile at you while hiding a CAPTCHA behind their back. May your proxies stay fresh, your user agents convincing, and your CSVs full of actual product data.
Want more tips, proxy configs, and hands-on guidance from other scrapers in the trenches? Join us on our Discord channel - we’d love to have you.
Until next time!
Is web scraping allowed on Amazon?
Amazon’s robots.txt file blocks bots, and its terms clearly say, “Don’t scrape.” But violating terms isn’t always the same as breaking the law. What matters is whether your scraping causes harm, violates user privacy, or misuses the data.
Does Amazon allow price scraping?
Amazon doesn’t allow price scraping under its official rules. But scraping prices from publicly visible product pages isn’t always illegal; it depends on your methods, your intent, and how responsibly you go about it.
Does Amazon block web scrapers?
Absolutely. Our code is all the evidence you need to know Amazon doesn’t just block scrapers - it plays mind games with them. Instead of showing you a hard error, it often pretends everything is fine with fake pages, missing data, or stealth CAPTCHAs.
How to scrape Amazon without getting blocked?
Think like Amazon. They expect bots to repeat themselves, rush, or act in a robotic manner. So slow down. Switch up your IPs. Use realistic headers. Back off when you’re blocked. And always verify your data. Just because it says 200 OK doesn’t mean it’s real.
What are the best tools for scraping Amazon?
It depends on how deep you want to go. For basic jobs, requests and BeautifulSoup are a solid combination. But if you need to deal with JavaScript, CAPTCHAs, or fake pages, headless browsers like Playwright, Selenium, or Puppeteer are your best bet. And don’t forget smart proxy services.



