
The world is becoming increasingly reliant on data-driven decision-making. It's important for every developer to be aware of web scraping techniques to extract data from the internet. With that in mind, in this article, you'll learn how to:
- Install the Golang development environment, including the libraries and dependencies.
- Build a simple Go web scraping bot from scratch.
- Implement advanced Golang data scraping techniques.
- Optimize your scraper for maximum performance.
- Test and maintain your Golang scraping bot.
Join us below!
What Is Golang Web Scraping?
Web scraping is the process of automatically extracting data from websites. A company like Walmart must ensure its product prices are either lower than or match those of competitors like Amazon to stay competitive. If Amazon is your scraping target, our guide on Amazon web scraping covers the platform-specific techniques and anti-bot challenges you'll need to handle. However, manually collecting product price data for thousands—or even millions—of products is time-consuming.
To gather this information, companies use web scrapers that automatically extract data from thousands of product pages quickly and efficiently. These tools operate based on coded instructions to perform specific tasks.
If you're thinking of implementing a web scraping tool, you have two options: buy a pre-built bot or develop one yourself. While the former offers some convenience, you ultimately lose essential customization features that only a custom, in-house scraper can provide.
That's why it's better to learn how to build your own data scraper. To do so, you'll need to use a programming language. There are many options here, each with its own pros and cons. Golang, for instance, is an excellent choice. Here's why:
- High performance
Golang is compiled into machine code. This makes it faster than interpreted languages like Python and JavaScript.
- Built-in support for concurrency
Golang offers native routines for concurrency using Goroutines, allowing your web scraping bot to handle multiple tasks simultaneously.
- Lightweight and memory-efficient
Golang is designed to be minimal, with efficient memory management. This helps reduce memory bloat when working with large datasets.
- Rich standard library
Golang comes with a comprehensive standard library that includes net/http for making web requests, html/template for parsing HTML, and encoding/json for processing JSON data.
If you're wondering what you can achieve using Golang data scraping methods, keep reading to find out.
Use Cases for Web Scraping in Golang
Below are the different web scraping applications in 2024:
- Market analysis
Web scraping allows companies to extract information about competitors' pricing, products, and overall marketing strategy. With this intelligence, businesses can adjust their strategies to remain competitive.
- Sentiment analysis
Brand reputation is essential to the success of any business. Companies extract customer opinion and sentiment data from review sites like Trustpilot and social media platforms such as Instagram. This information is then used to guide brand-building initiatives.
- Lead generation
Web scrapers can also extract contact information from various directories like LinkedIn, Yelp, and business directories. Businesses then use these details to identify potential clients and generate leads.
- Data mining for AI models
Scraping bots also collect data necessary for training the large AI models behind the mainstream explosion of chatbots like ChatGPT and Gemini.
These are just a few examples of how web scraping is helping businesses across industries. With the right information, there’s little you can't achieve—whether it’s training an AI model to automate tasks, gathering market intelligence, or meeting any other data-driven need.
What Do You Need to Build a Go Web Scraper?
By now, you understand why web scraping is important—it all comes down to the value of the extracted data. But how do you build a Go data scraper from scratch? The process is simpler than you might think. Before diving in, make sure you have all the prerequisites installed.
Setting up the Golang Development Environment
First, make sure Golang is installed on your device. If it isn’t, follow this step-by-step guide for all major operating systems:
Mac OS
- Step 1: Open your browser and head over to the Go official website to download the .pkg package for macOS:
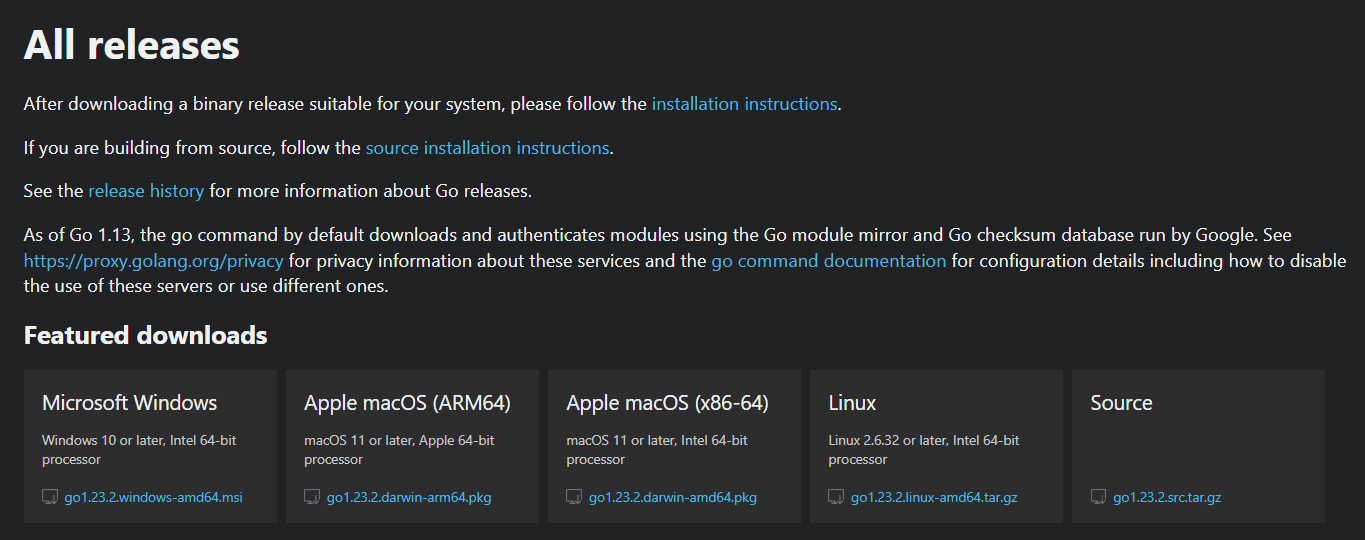
- Step 2: Open the downloaded file and follow the installation instructions. Click "Continue" to accept the terms.
- Step 3: Edit your shell configuration file based on the shell you use. Here's the code for bash users:
nano ~/.bash_profile
- Step 4: Edit your zsh configuration file (skip if you use bash):
nano ~/.zshrc
Step 5: Add the following line to the file:
export PATH=$PATH:/usr/local/go/bin
Step 6: Run the following code to reload the configuration file:
source ~/.zshrc // for zsh
source ~/.zshrc //for bash
Step 7: Use this command to verify the installation:
go version
You should now see the installed Go version on your screen.
Windows OS
- Step 1: Go to the official Go website and download the .msi installer as shown below:
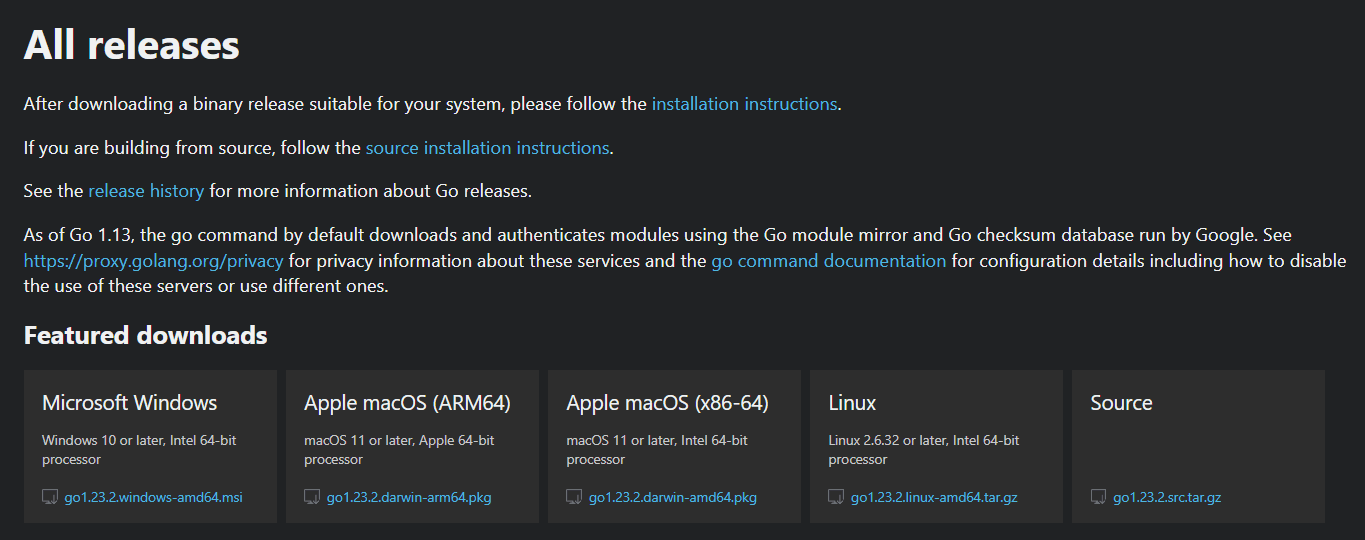
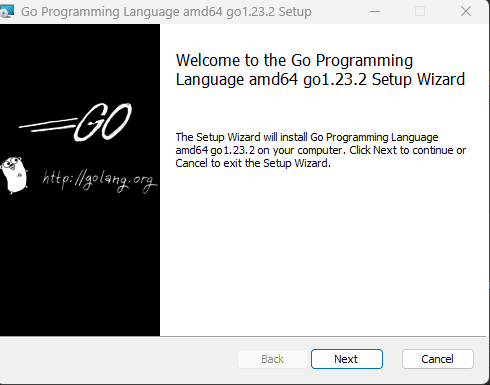
Step 2: Open the downloaded file and accept the license, then click "Next."
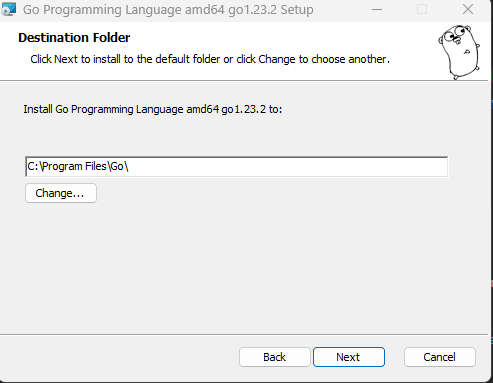
Step 3: Choose a folder for the installation files and click "Next" for the installation process:
Step 4: To verify the installation, open your command prompt and type the following command:
go version
If installed correctly, you should see the Go version on your screen.
Linux OS
Linux users have two options for installing Go: either using the official binary or the package manager.
Option 1: Using the Official Binary
- Step 1: Visit the official Go website and download the appropriate .tar.gz file for your system architecture:
- Step 2: Open your terminal and run the following code to extract the archive:
sudo tar -C /usr/local -xzf go<version>.linux-amd64.tar.gz
- Step 3: If you use bash, add the following line to your shell configuration file to set up the environment variables:
nano ~/.bashrc
- Step 4: For zsh users, add the following line to your shell configuration file (skip if you followed step 3):
nano ~/.zshrc
Step 5: Add the following command to your configuration file:
export PATH=$PATH:/usr/local/go/bin
- Step 6: Reload the configuration file:
source ~/.bashrc # Or use ~/.zshrc if using zsh
- Step 7: Verify the installation using the following command:
go version
You should see the Go version on your screen.
Option 2: Using Package Manager (Ubuntu/Debian)
- Step 1: Update the package list using the following command:
sudo apt update
- Step 2: Install Go:
sudo apt install golang-go
- Step 3: Verify the installation:
go version
If installed correctly, you should see the Go version on your screen.
Required Libraries and Dependencies
Now that Go is installed on your device, the next step is configuring the libraries and dependencies that the web scraper will need. Start with these libraries:
- Goquery
This is a powerful Go library that allows you to easily manipulate and query HTML documents. It can select, filter, and extract information from web pages using a CSS selector. Write the following command in your terminal to install Goquery:
go get github.com/PuerkitoBio/goquery
- Colly
The Colly web scraper is a high-level framework written in Go. It simplifies the process of sending requests to websites, handling the responses, and managing scraping flows. Use the following command to install Colly on your system:
go get github.com/gocolly/colly/v2
By this point, you're all set to start building your Golang data scraper. You have installed Go and the basic dependencies on your system. Now, to the crux of our discussion:
How to Build a Simple Web Scraper in Golang (Step-by-Step Guide)
We're going to code a simple data scraper to collect book titles from books.toscrape.com. To be clear, this is a fictional online bookstore purposely created as a playground for web scraping enthusiasts. Let's get to it:
Step 1: Declare Your Package
Every Go program must start with a package declaration. Here is the command to declare your package:
package main
Step 2: Import the Required Packages
The following code will import the required packages to help our web scraper extract data:
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
Here is what it means:
- fmt: Provides functions to print output to the console.
- log: Helps log messages and errors.
- net/http: Provides the tools to send HTTP requests and receive responses.
- github.com/PuerkitoBio/goquery: A third-party library that makes HTML parsing easier by providing jQuery-like syntax.
Step 3: Write the Main Function
The main() function is the entry point to the Golang code. We'll break it down into its individual components:
First, you must declare the main function using this code:
func main() {
Next, you want to declare the URL we will be scraping:
url := "http://books.toscrape.com"
We now want to instruct the bot to send an HTTP request to this URL and retrieve the response. If the program encounters any error such as the website being down. It automatically stops the program and prints an error message. Use this code:
resp, err := http.Get(url)
if err != nil {
log.Fatalf("Error fetching URL %s: %v", url, err)
}
defer resp.Body.Close()
Once the bot retrieves the HTML content, we want it to read the content using a goquery document. Again, if this process fails, the bot should stop the program and return an error message. Use this code:
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatalf("Error parsing HTML: %v", err)
}
To make the output easy to follow, we will need to print "Book Titles" as a header message. Use the following code:
fmt.Println("Book Titles:")
We will now need to write the section of the bot that automatically selects the book titles to print as the output. Use the following code to select h3 tags to print:
doc.Find(".product_pod h3 a").Each(func(index int, item *goquery.Selection) {
title, exists := item.Attr("title")
if exists {
fmt.Printf("Book %d: %s\n", index+1, title)
}
})
To finish off your code, you must write the callback function to facilitate asynchronous execution and print the titles:
func(index int, item *goquery.Selection) {
title, exists := item.Attr("title")
if exists {
fmt.Printf("Book %d: %s\n", index+1, title)
}
}
Step 4: Bring It All Together
Now to join all the sections for the full script:
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func main() {
url := "http://books.toscrape.com"
// Send HTTP GET request
resp, err := http.Get(url)
if err != nil {
log.Fatalf("Error fetching URL %s: %v", url, err)
}
defer resp.Body.Close()
// Parse the HTML response using goquery
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatalf("Error parsing HTML: %v", err)
}
fmt.Println("Book Titles:")
// Find book titles inside <h3> tags
doc.Find(".product_pod h3 a").Each(func(index int, item *goquery.Selection) {
title, exists := item.Attr("title")
if exists {
fmt.Printf("Book %d: %s\n", index+1, title)
}
})
}
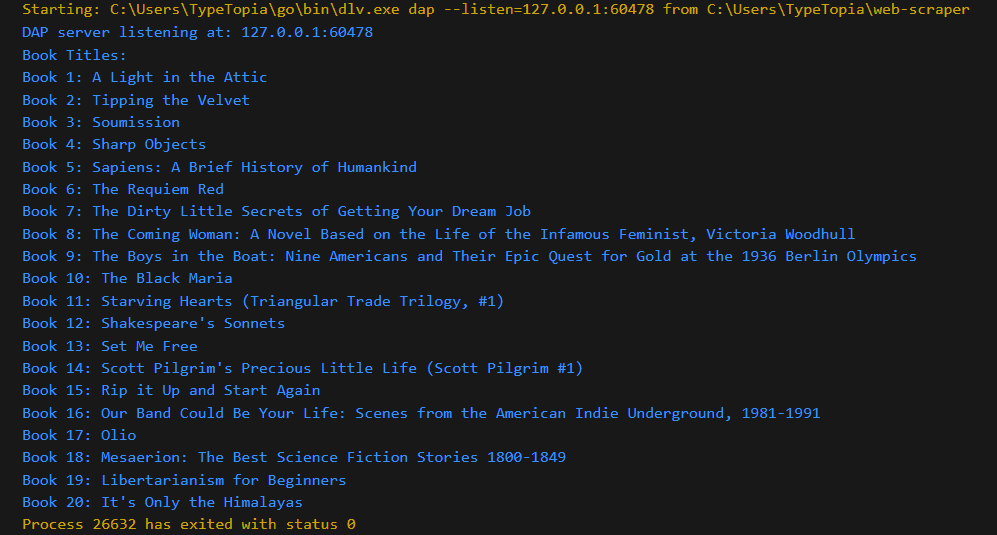
If you follow all the steps correctly, you should see the book titles from Books to Scrape as output like so:
Modifying Your Go Code to Scrape Data from Multiple Pages
The scraping bot we just built can only collect book titles from the first page of Books to Scrape. If you want to collect data from, say, the first five pages, you would need to declare the base URL and make a couple of changes to your main function in Step 3 above. Here are the steps you need to take to modify the code:
Step 1: Define the Base URL
After importing the packages (use the same packages as before), you must define the base URL upon which the bot will construct the next page's URL during pagination:
const baseURL = "http://books.toscrape.com"
Step 2: Modify Your Main Function
You want your main function to instruct the bot to start scraping the first page of the website. Here is the new main function:
func main() {
scrapePage(baseURL, 1) // Start scraping from page 1
}
Step 3: Add a Function to Scrape a Single Page
Next, you must add a function that will scrape a single URL before moving to the next one. Here is the code to use:
func scrapePage(url string, pageNumber int) {
fmt.Printf("\nScraping Page %d: %s\n", pageNumber, url)
// Send HTTP request
resp, err := http.Get(url)
if err != nil {
log.Fatalf("Error fetching URL %s: %v", url, err)
}
defer resp.Body.Close()
// Parse the HTML response
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatalf("Error parsing HTML: %v", err)
}
// Extract and print book titles for the current page
doc.Find(".product_pod h3 a").Each(func(index int, item *goquery.Selection) {
title, exists := item.Attr("title")
if exists {
fmt.Printf("Book %d: %s\n", index+1, title)
}
})
// Find the link to the next page
nextPage, exists := doc.Find(".next a").Attr("href")
if exists {
nextURL := baseURL + "/" + nextPage // Build the full URL for the next page
scrapePage(nextURL, pageNumber+1) // Recursively scrape the next page with incremented page number
} else {
fmt.Println("\nNo more pages to scrape.")
}
}
Here's what all this means:
- The function starts by printing the page number and the URL of the page being scraped.
- It then sends an HTTP request to this specific URL, and if there's a problem, it logs the error and stops the execution.
- If the bot successfully retrieves the HTML content, it will parse this response using Goquery.
- Once parsed, it will then find the specific HTML elements that have the book titles and print the titles along with their index.
- After completing one page, the bot looks for the link to the next page by searching for the .next a element. The function then recursively calls the scrapePage function to scrape the next page.
If there are no more pages to scrape, the bot prints this message and terminates the program.
Step 4: New Code to Scrape Multiple Pages
Merging all the modifications you've made so far, here's the modified code:
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
// Base URL for the website
const baseURL = "http://books.toscrape.com"
func main() {
scrapePage(baseURL, 1) // Start scraping from page 1
}
// Function to scrape a single page and handle pagination
func scrapePage(url string, pageNumber int) {
fmt.Printf("\nScraping Page %d: %s\n", pageNumber, url)
// Send HTTP GET request
resp, err := http.Get(url)
if err != nil {
log.Fatalf("Error fetching URL %s: %v", url, err)
}
defer resp.Body.Close()
// Parse the HTML response
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatalf("Error parsing HTML: %v", err)
}
// Extract and print book titles for the current page
doc.Find(".product_pod h3 a").Each(func(index int, item *goquery.Selection) {
title, exists := item.Attr("title")
if exists {
fmt.Printf("Book %d: %s\n", index+1, title)
}
})
// Find the link to the next page
nextPage, exists := doc.Find(".next a").Attr("href")
if exists {
nextURL := baseURL + "/" + nextPage // Build the full URL for the next page
scrapePage(nextURL, pageNumber+1) // Recursively scrape the next page with incremented page number
} else {
fmt.Println("\nNo more pages to scrape.")
}
}
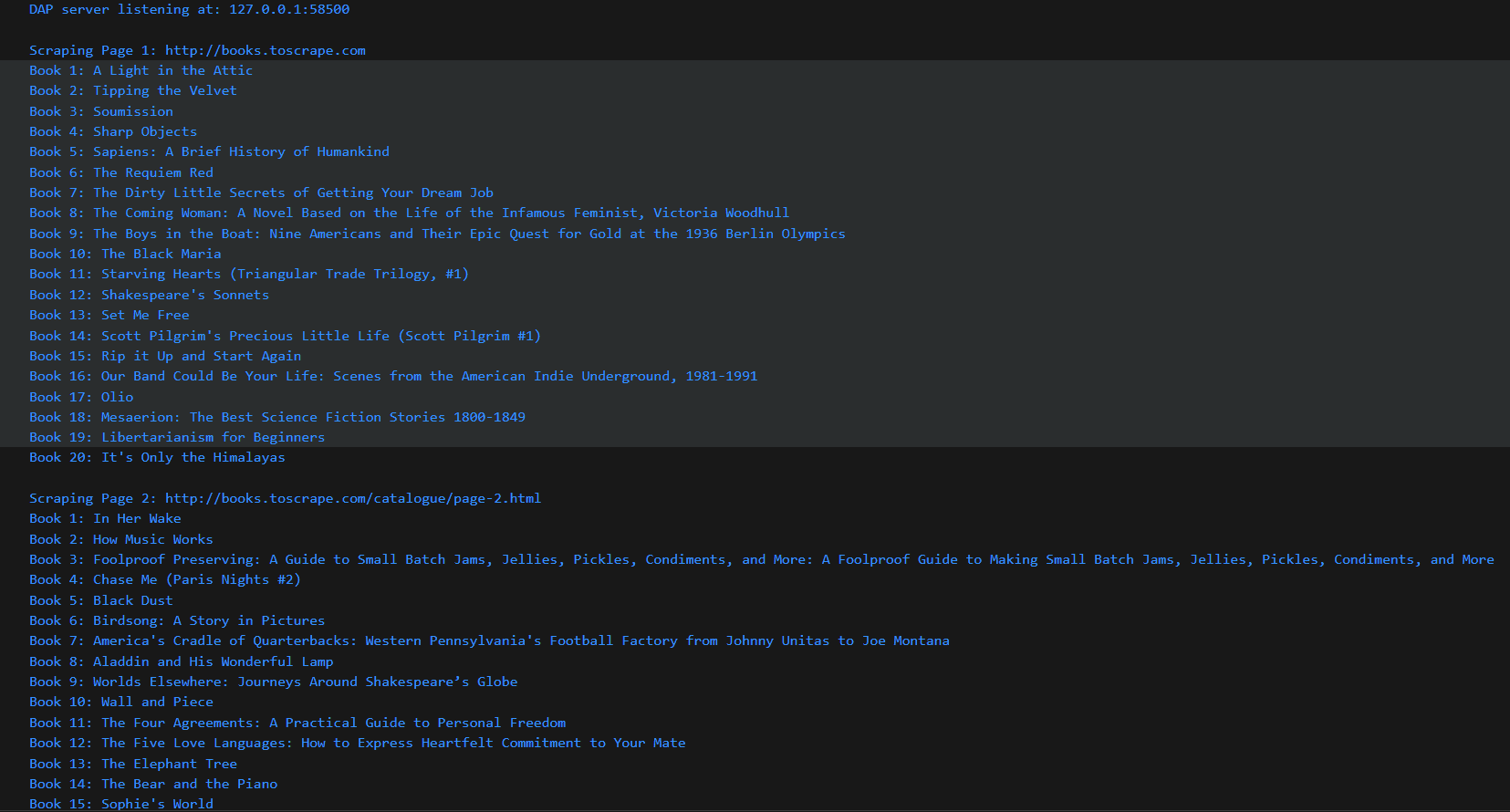
Below is the response after running this Go web scraping code:
Advanced Golang Web Scraping Techniques
Up to this point, you know how to write the code for a basic data scraper that can perform data extraction from Books to Scrape. Now, we're going to take things a notch higher by diving into the steps you can take to optimize your code for maximum performance.
Handling JavaScript-heavy Websites
Have you ever come across a website with an infinite scrolling feed? As you scroll, the page updates in real-time, offering a faster and enhanced user experience. Examples include platforms like Twitter and Facebook. These websites use JavaScript to render dynamic content.
If you attempt to scrape such sites using the code above, you’ll encounter issues because the net/http libraries only fetch the initial HTML content loaded by the server. This poses a challenge since JavaScript websites may not always send the complete content in the initial server response.
So, how do you scrape data from these sites using Golang?
Let's try collecting data from a JavaScript website to find out. A good example is Quotes to Scrape, the JavaScript-heavy alternative to Books to Scrape—join us in developing a bot to collect data from this website below:
Step 1: Install Chromedp
Traditional tools like net/http and Goquery can only fetch static HTML. Chromedp, on the other hand, behaves like a real web browser: it loads JavaScript, renders the page fully, and interacts with dynamic elements such as buttons or scrolling pages. Use the following command to install Chromedp in your system:
go get -u github.com/chromedp/chromedp
Once installed, you can now write the Go data scraper code to retrieve data from the Quotes to Scrape website. Let's continue:
Step 2: Declare Your Packages
Use the following command to declare the packages the bot will use:
package main
Step 3: Import Your Packages
Use the same packages we've been using all along:
import (
"context"
"fmt"
"log"
"time"
"github.com/chromedp/chromedp"
)
Step 4: Write Your Main Function
Step 4: Write Your Main Function
The main function for this scraper has several components. We will explain them below. Here is the code:
func main() {
// Create a context with timeout to manage the browser session
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
ctx, cancel = context.WithTimeout(ctx, 15*time.Second)
defer cancel()
var bookTitles []string
// Navigate to the target site and scrape book titles
err := chromedp.Run(ctx,
chromedp.Navigate("https://quotes.toscrape.com/js/"), // Change to your dynamic page URL
chromedp.WaitVisible(".quote", chromedp.ByQuery), // Wait for elements to load
chromedp.Evaluate(`
[...document.querySelectorAll('.quote .text')].map(el => el.innerText);
`, &bookTitles), // Collect all book titles or quotes into bookTitles slice
)
if err != nil {
log.Fatalf("Failed to scrape the page: %v", err)
}
// Print the collected titles
fmt.Println("Book Titles / Quotes:")
for i, title := range bookTitles {
fmt.Printf("Item %d: %s\n", i+1, title)
}
}
Here's what it all means:
- Create a context with timeout
If the dynamic content page takes too long to load, we must set a timeout that prevents our scraper from hanging. That's what the first part of the main function does.
- Use Chromedp's Navigate to open the web page
Next, we use chromedp.Navigate() to open a headless browser session (You may notice a white blank window appearing on your device).
- Use WaitVisible to ensure content loads
When interacting with JavaScript-heavy sites, content is not usually loaded at once, so we must wait for the content we want to load fully before we attempt to scrape it.
- Replace Goquery with JavaScript Evaluation to extract data
You must allow JavaScript time to finish fetching the HTML content sent after the page has loaded before you attempt to collect data. To do that, we use the chromedp.Evaluate() function to run JavaScript inside the browser session and extract the content after it has loaded.
In case of any issues during execution, the bot will stop and print an error message. If successful, the scraper will print the titles of the collected items.
Step 5: Run the Full Code
Here is the full code to collect JavaScript content from Quotes to Scrape:
package main
import (
"context"
"fmt"
"log"
"time"
"github.com/chromedp/chromedp"
)
func main() {
// Create a context with timeout to manage the browser session
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()
ctx, cancel = context.WithTimeout(ctx, 15*time.Second)
defer cancel()
var bookTitles []string
// Navigate to the target site and scrape book titles
err := chromedp.Run(ctx,
chromedp.Navigate("https://quotes.toscrape.com/js/"), // Change to your dynamic page URL
chromedp.WaitVisible(".quote", chromedp.ByQuery), // Wait for elements to load
chromedp.Evaluate(`
[...document.querySelectorAll('.quote .text')].map(el => el.innerText);
`, &bookTitles), // Collect all book titles or quotes into bookTitles slice
)
if err != nil {
log.Fatalf("Failed to scrape the page: %v", err)
}
// Print the collected titles
fmt.Println("Book Titles / Quotes:")
for i, title := range bookTitles {
fmt.Printf("Item %d: %s\n", i+1, title)
}
}
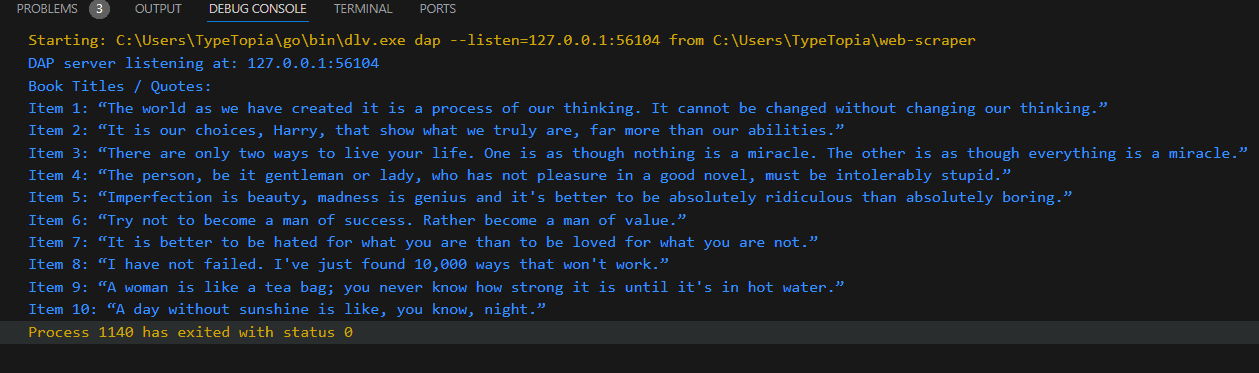
If all goes well, you should get the following response:
Working with APIs and JSON Responses in Golang
Some websites provide APIs that allow users to request specific data. A good example is Twitter (no one really calls it X); you can retrieve tweets, user information, and trends from the Twitter API, although access to such information has changed in recent years. Either way, scraping data from an API that provides JSON responses is efficient because there's no need to parse the HTML content. At the same time, there's less risk of legal issues since most APIs have public terms of service that guide usage.
Let's modify our web scraping script to collect data from the JSONPlaceholder API, which provides fake data for practicing API-based data extraction methods. The API has six common resources you can use:
- Posts (100 posts): https://jsonplaceholder.typicode.com/posts
- Comments (500 comments): https://jsonplaceholder.typicode.com/comments
- Albums (100 albums): https://jsonplaceholder.typicode.com/albums
- Photos (5000 photos): https://jsonplaceholder.typicode.com/photos
- Todos (200 todos): https://jsonplaceholder.typicode.com/todos
- Users (10 users): https://jsonplaceholder.typicode.com/users
So how does it work? Let's write a code to retrieve the first 10 blog post titles from /posts.
Step 1: Declare Your Main Package with the Following Command
package main
Step 2: Use the Following Code to Import the Required Packages
i
mport (
"encoding/json"
"fmt"
"log"
"net/http"
)
Here's what it all means:
- encoding/json: Handles the conversion between JSON data and Go structs.
- fmt: Provides functions like Printf and Println for printing text to the console.
- log: For logging errors and debugging messages.
- net/http: Sends HTTP requests and retrieves responses from APIs.
Step 3: Define the Post Struct
Use the following code to define your Post struct:
type Post struct {
UserID int `json:"userId"`
ID int `json:"id"`
Title string `json:"title"`
Body string `json:"body"`
}
This struct will model the structure of each post returned by the API, with field names like UserID and ID corresponding to the JSON keys in the API response.
Step 4: Write Your Main Function
Your main function will have several components, as shown below:
func main() {
url := "https://jsonplaceholder.typicode.com/posts"
resp, err := http.Get(url)
if err != nil {
log.Fatalf("Error fetching posts: %v", err)
}
defer resp.Body.Close()
var posts []Post
if err := json.NewDecoder(resp.Body).Decode(&posts); err != nil {
log.Fatalf("Error decoding JSON: %v", err)
}
fmt.Println("First 10 Blog Post Titles:")
for i := 0; i < 10; i++ {
fmt.Printf("%d. %s\n", i+1, posts[i].Title)
}
}
Let's take a closer look at the main function:
- It begins by defining the URL endpoint from which we will be collecting data.
- It then sends an HTTP GET request to this endpoint, and if the request fails, it aborts the logic and prints an error message.
- The bot then decodes the extracted JSON data into structs and prints the titles incrementally for the first ten blog posts.
Step 5: Bring It All Together
Here is the full code for your JSON API scraper:
package main
import (
"encoding/json"
"fmt"
"log"
"net/http"
)
// Struct to map the JSON structure of each post
type Post struct {
UserID int `json:"userId"`
ID int `json:"id"`
Title string `json:"title"`
Body string `json:"body"`
}
func main() {
url := "https://jsonplaceholder.typicode.com/posts"
resp, err := http.Get(url)
if err != nil {
log.Fatalf("Error fetching posts: %v", err)
}
defer resp.Body.Close()
var posts []Post
if err := json.NewDecoder(resp.Body).Decode(&posts); err != nil {
log.Fatalf("Error decoding JSON: %v", err)
}
fmt.Println("First 10 Blog Post Titles:")
for i := 0; i < 10; i++ {
fmt.Printf("%d. %s\n", i+1, posts[i].Title)
}
}
Once you run the code, it should print a list of the first 10 blog titles as follows:
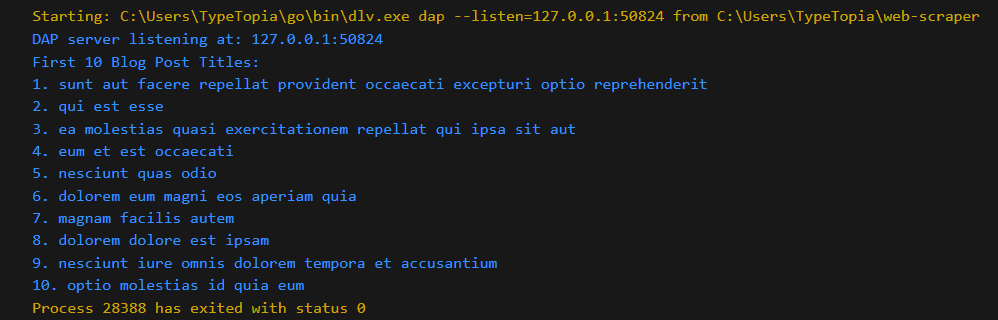
Avoiding Detection: How to Bypass Scraping Blocks
By this point, you can confidently consider yourself a novice at web scraping techniques. You know how to use Golang to extract static data from traditional HTML websites, dynamic websites that use JavaScript, and APIs that provide data in JSON format.
But before you start putting all this knowledge into practice, there's one thing you should know: Most websites are apprehensive toward web scrapers. While the robots.txt file may allow for scraping, websites can still ban or restrict your IP when it sends too many scraping requests.
To fix that, use a pool of residential proxies, upon which your Golang scraper will rotate its data extraction requests. Let's modify the code we used to fetch the first 10 titles from the Posts resource of the JSON API. Go back to your code and modify the following steps:
Modify Step 3 to Import Additional Libraries for Proxy Rotation
Here are the additional packages to import:
import (
"encoding/json"
"fmt"
"log"
"net/http"
"net/url"
"strings"
"time"
)
- net/url: For parsing and working with URLs.
- strings: For string manipulation.
- time: For setting timeouts and rate limits.
New Step 4: to Add Your Proxies List
Step 3, where you defined the Post struct function, remains the same. However, before you declare the main function, you must first add the proxy list variable that will facilitate rerouting your requests through the new pool of IPs. Feel free to modify the list with your own proxy IPs:
var proxies = []string{
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=2n39i3ia&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=7ric72rl&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=jvtuogsy&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=po3xt1w7&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=88gijk21&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=wes8szpl&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=ntsyd9ux&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=5myzrqnk&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=80ow4rs7&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=i7f4cx3y&_lifetime=30m",
}
New Step 5: Define a Function to Create an HTTP Client with a Proxy
Use the following code to create this function:
func createProxyClient(proxyURL string) (*http.Client, string) {
parsedURL, err := url.Parse(proxyURL)
if err != nil {
log.Fatalf("Failed to parse proxy URL %s: %v", proxyURL, err)
}
proxyIP := strings.Split(parsedURL.Host, ":")[0]
transport := &http.Transport{
Proxy: http.ProxyURL(parsedURL),
}
return &http.Client{
Transport: transport,
Timeout: 15 * time.Second,
}, proxyIP
}
Because we want each request to be sent through a different IP address, this function ensures that the proxy is applied by creating an HTTP client.
New Step 6: Create a Function to Scrape a Single URL
Next, you must write a function to scrape a single URL. Here it is:
// Function to scrape a single URL
func scrapeURL(targetURL string, proxy string) {
client, proxyIP := createProxyClient(proxy) // Create an HTTP client with the proxy
resp, err := client.Get(targetURL)
if err != nil {
log.Printf("Failed to fetch %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
defer resp.Body.Close()
var post Post
if err := json.NewDecoder(resp.Body).Decode(&post); err != nil {
log.Printf("Error decoding JSON from %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
This function will scrape the target URL using the HTTP client we created and its associated proxy IP. It will then decode the JSON response into a Post struct and print this title along with the proxy that was used.
New Step 7 (Old Step 4): Modify Your Main Function
Previously, your main function only retrieved the title of the blog post and then repeated the extraction process for the first ten blog posts. We now want to use proxies to send each request using a different IP address randomly selected from the pool we defined in Step 4. Use the following code:
func main() {
urls := []string{
"https://jsonplaceholder.typicode.com/posts/1",
"https://jsonplaceholder.typicode.com/posts/2",
"https://jsonplaceholder.typicode.com/posts/3",
"https://jsonplaceholder.typicode.com/posts/4",
"https://jsonplaceholder.typicode.com/posts/5",
"https://jsonplaceholder.typicode.com/posts/6",
"https://jsonplaceholder.typicode.com/posts/7",
"https://jsonplaceholder.typicode.com/posts/8",
"https://jsonplaceholder.typicode.com/posts/9",
"https://jsonplaceholder.typicode.com/posts/10",
}
// Scrape each URL using a different proxy
for i, url := range urls {
proxy := proxies[i%len(proxies)] // Rotate proxies
scrapeURL(url, proxy) // Scrape the URL
}
fmt.Println("All requests completed.")
}
This code block begins by listing the URLs to scrape. It then rotates the requests through the different IPs in the pool we defined in Step 4 by calling the functions we defined in Steps 5 and 6.
Step 8: Run the Full Modified Code
Here is the complete modified code to run:
package main
import (
"encoding/json"
"fmt"
"log"
"net/http"
"net/url"
"strings"
"time"
)
// Struct to map the API JSON response
type Post struct {
UserID int `json:"userId"`
ID int `json:"id"`
Title string `json:"title"`
Body string `json:"body"`
}
// List of proxies with username-password authentication
var proxies = []string{
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=2n39i3ia&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=7ric72rl&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=jvtuogsy&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=po3xt1w7&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=88gijk21&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=wes8szpl&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=ntsyd9ux&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=5myzrqnk&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=80ow4rs7&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=i7f4cx3y&_lifetime=30m",
}
// Function to create an HTTP client with a proxy
func createProxyClient(proxyURL string) (*http.Client, string) {
parsedURL, err := url.Parse(proxyURL)
if err != nil {
log.Fatalf("Failed to parse proxy URL %s: %v", proxyURL, err)
}
// Extract the proxy IP from the parsed URL's Host
proxyIP := strings.Split(parsedURL.Host, ":")[0]
transport := &http.Transport{
Proxy: http.ProxyURL(parsedURL),
}
return &http.Client{
Transport: transport,
Timeout: 15 * time.Second,
}, proxyIP
}
// Scrape a URL using the proxy-enabled client
// Function to scrape a single URL
func scrapeURL(targetURL string, proxy string) {
client, proxyIP := createProxyClient(proxy) // Create an HTTP client with the proxy
resp, err := client.Get(targetURL)
if err != nil {
log.Printf("Failed to fetch %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
defer resp.Body.Close()
var post Post
if err := json.NewDecoder(resp.Body).Decode(&post); err != nil {
log.Printf("Error decoding JSON from %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
fmt.Printf("Fetched post %d: %s (via proxy: %s)\n", post.ID, post.Title, proxyIP)
}
func main() {
urls := []string{
"https://jsonplaceholder.typicode.com/posts/1",
"https://jsonplaceholder.typicode.com/posts/2",
"https://jsonplaceholder.typicode.com/posts/3",
"https://jsonplaceholder.typicode.com/posts/4",
"https://jsonplaceholder.typicode.com/posts/5",
"https://jsonplaceholder.typicode.com/posts/6",
"https://jsonplaceholder.typicode.com/posts/7",
"https://jsonplaceholder.typicode.com/posts/8",
"https://jsonplaceholder.typicode.com/posts/9",
"https://jsonplaceholder.typicode.com/posts/10",
}
for i, url := range urls {
proxy := proxies[i%len(proxies)] // Rotate proxies
scrapeURL(url, proxy) // Scrape the URL
}
fmt.Println("All requests completed.")
}
Below is what to expect as output:
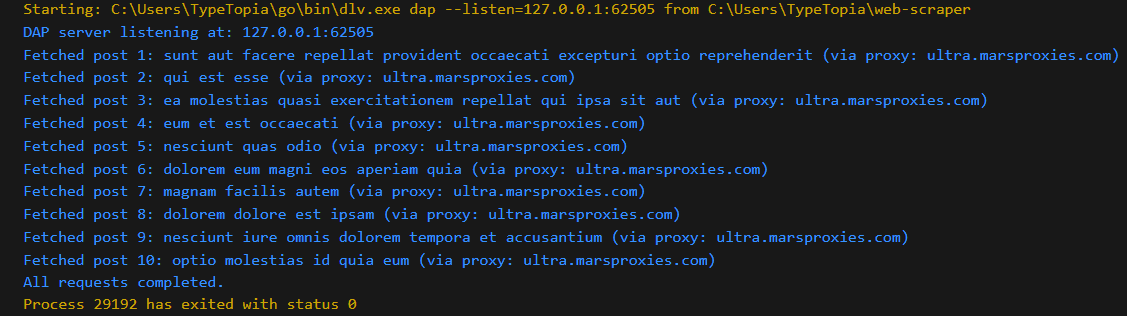
How to Optimize Your Golang Web Scraper for Maximum Performance
So far, you can create a Golang data scraper capable of extracting static or dynamic data from a website or API, depending on what's available. Let's take things up a notch by looking at ways to increase the performance of your bot. Specifically, we're going to make three major upgrades to the code we used to scrape data from the JSON Placeholder API:
- Enabling concurrency and parallelism using Goroutines: To improve speed and efficiency.
- Rate limiting and sleep intervals: To control the frequency of requests to avoid overloading the servers and getting blocked.
- Memory management: To handle large datasets efficiently.
Let's dive in.
Enabling Concurrency and Parallelism Using Goroutines
To improve the speed and efficiency of our scraper using Goroutines, you must do the following:
- Modify Step 3 to import the Sync package
In Golang, Goroutines allows you to execute functions concurrently. To use them, first import the sync package in Step 3. Here is the modified code for Step 3:
import (
"encoding/json"
"fmt"
"log"
"net/http"
"net/url"
"strings"
"sync" // Added sync package
"time"
)
- Modify Step 6 to add a WaitGroup parameter that tracks the completion of all Goroutines
Here is the modified function:
// Add WaitGroup as a parameter to track completion of all Goroutines
func scrapeURL(targetURL string, proxy string, wg *sync.WaitGroup) {
defer wg.Done() // Ensure the WaitGroup counter is decremented
client, proxyIP := createProxyClient(proxy)
resp, err := client.Get(targetURL)
if err != nil {
log.Printf("Failed to fetch %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
defer resp.Body.Close()
var post Post
if err := json.NewDecoder(resp.Body).Decode(&post); err != nil {
log.Printf("Error decoding JSON from %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
fmt.Printf("Fetched post %d: %s (via proxy: %s)\n", post.ID, post.Title, proxyIP)
}
Adding Rate Limiting and Sleep Intervals
Adding rate limiting and sleep intervals ensures the target server is not overwhelmed, and your bot mimics human behavior to avoid detection. Here's how you can upgrade the code:
- Modify Step 3 to add a new package
You must import the math/rand package for random sleep intervals. Here is the modified code for Step 3:
package main
import (
"encoding/json"
"fmt"
"log"
"math/rand" // For random sleep intervals
"net/http"
"net/url"
"strings"
"sync"
"time"
- Modify Step 5 to create a channel that sends a request every two seconds
Each Goroutine will wait for two seconds before sending a request. Within the same block, introduce randomized sleep intervals to mimic real user behavior, as shown in the following code:
var limiter = time.Tick(2 * time.Second) // 1 request every 2 seconds
func scrapeURL(targetURL string, proxy string, wg *sync.WaitGroup) {
defer wg.Done()
<-limiter // Wait for the tick to proceed
client, proxyIP := createProxyClient(proxy)
resp, err := client.Get(targetURL)
if err != nil {
log.Printf("Failed to fetch %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
defer resp.Body.Close()
var post Post
if err := json.NewDecoder(resp.Body).Decode(&post); err != nil {
log.Printf("Error decoding JSON from %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
fmt.Printf("Fetched post %d: %s (via proxy: %s)\n", post.ID, post.Title, proxyIP)
// Random sleep interval between 1-3 seconds
time.Sleep(time.Duration(1 + rand.Intn(3)) * time.Second)
}
Memory Management for Large-Scale Scraping Projects
To manage memory when working with large datasets, you should implement buffered channels to temporarily store collected information. You'll need to modify Step 5 to create a buffered channel to store the results and send the collected information to this buffer.
// Create a rate limiter to enforce delay between requests
var limiter = time.Tick(2 * time.Second) // 1 request every 2 seconds
// Buffered channel to collect scraping results
var results = make(chan Post, 10) // Store up to 10 posts
// Function to scrape a URL and send the result to the buffered channel
func scrapeURL(targetURL string, proxy string, wg *sync.WaitGroup) {
defer wg.Done() // Decrement WaitGroup counter when done
<-limiter // Wait for the tick to proceed
client, proxyIP := createProxyClient(proxy)
resp, err := client.Get(targetURL)
if err != nil {
log.Printf("Failed to fetch %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
defer resp.Body.Close()
var post Post
if err := json.NewDecoder(resp.Body).Decode(&post); err != nil {
log.Printf("Error decoding JSON from %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
// Send the result to the buffered channel
results <- post
fmt.Printf("Fetched post %d: %s (via proxy: %s)\n", post.ID, post.Title, proxyIP)
// Random sleep interval to simulate human behavior (1-3 seconds)
time.Sleep(time.Duration(1+rand.Intn(3)) * time.Second)
}
Bringing It Together: Optimized Go Scraper Code
Once you make all the modifications we've discussed to upgrade your scraper, your script should look like this:
package main
import (
"encoding/json"
"fmt"
"log"
"math/rand" // For random sleep intervals
"net/http"
"net/url"
"strings"
"sync"
"time"
)
// Struct to map the API JSON response
type Post struct {
UserID int `json:"userId"`
ID int `json:"id"`
Title string `json:"title"`
Body string `json:"body"`
}
// List of proxies with username-password authentication
var proxies = []string{
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=2n39i3ia&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=7ric72rl&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=jvtuogsy&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=po3xt1w7&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=88gijk21&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=wes8szpl&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=ntsyd9ux&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=5myzrqnk&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=80ow4rs7&_lifetime=30m",
"http://mr45184psO8:[email protected]:44443?_country=us&_state=alaska&_session=i7f4cx3y&_lifetime=30m",
}
// Create a rate limiter to enforce delay between requests
var limiter = time.Tick(2 * time.Second) // 1 request every 2 seconds
// Buffered channel to collect scraping results
var results = make(chan Post, 10) // Store up to 10 posts
// Function to create an HTTP client with a proxy
func createProxyClient(proxyURL string) (*http.Client, string) {
parsedURL, err := url.Parse(proxyURL)
if err != nil {
log.Fatalf("Failed to parse proxy URL %s: %v", proxyURL, err)
}
proxyIP := strings.Split(parsedURL.Host, ":")[0]
transport := &http.Transport{
Proxy: http.ProxyURL(parsedURL),
}
return &http.Client{
Transport: transport,
Timeout: 15 * time.Second,
}, proxyIP
}
// Function to scrape a URL and send the result to the buffered channel
func scrapeURL(targetURL string, proxy string, wg *sync.WaitGroup) {
defer wg.Done() // Decrement WaitGroup counter when done
<-limiter // Wait for the tick to proceed
client, proxyIP := createProxyClient(proxy)
resp, err := client.Get(targetURL)
if err != nil {
log.Printf("Failed to fetch %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
defer resp.Body.Close()
var post Post
if err := json.NewDecoder(resp.Body).Decode(&post); err != nil {
log.Printf("Error decoding JSON from %s using proxy %s: %v", targetURL, proxyIP, err)
return
}
// Send the result to the buffered channel
results <- post
fmt.Printf("Fetched post %d: %s (via proxy: %s)\n", post.ID, post.Title, proxyIP)
// Random sleep interval to simulate human behavior (1-3 seconds)
time.Sleep(time.Duration(1+rand.Intn(3)) * time.Second)
}
func main() {
// URLs to scrape
urls := []string{
"https://jsonplaceholder.typicode.com/posts/1",
"https://jsonplaceholder.typicode.com/posts/2",
"https://jsonplaceholder.typicode.com/posts/3",
"https://jsonplaceholder.typicode.com/posts/4",
"https://jsonplaceholder.typicode.com/posts/5",
"https://jsonplaceholder.typicode.com/posts/6",
"https://jsonplaceholder.typicode.com/posts/7",
"https://jsonplaceholder.typicode.com/posts/8",
"https://jsonplaceholder.typicode.com/posts/9",
"https://jsonplaceholder.typicode.com/posts/10",
}
var wg sync.WaitGroup // WaitGroup to manage Goroutines
for i, url := range urls {
proxy := proxies[i%len(proxies)] // Rotate proxies
wg.Add(1) // Increment WaitGroup counter
go scrapeURL(url, proxy, &wg) // Launch a Goroutine for each URL
}
// Launch a Goroutine to close the results channel after all requests complete
go func() {
wg.Wait() // Wait for all Goroutines to complete
close(results) // Close the channel when done
}()
// Process and print results from the buffered channel
for post := range results {
fmt.Printf("Processed post %d: %s\n", post.ID, post.Title)
}
fmt.Println("All requests completed.")
}
Below is the output to expect:
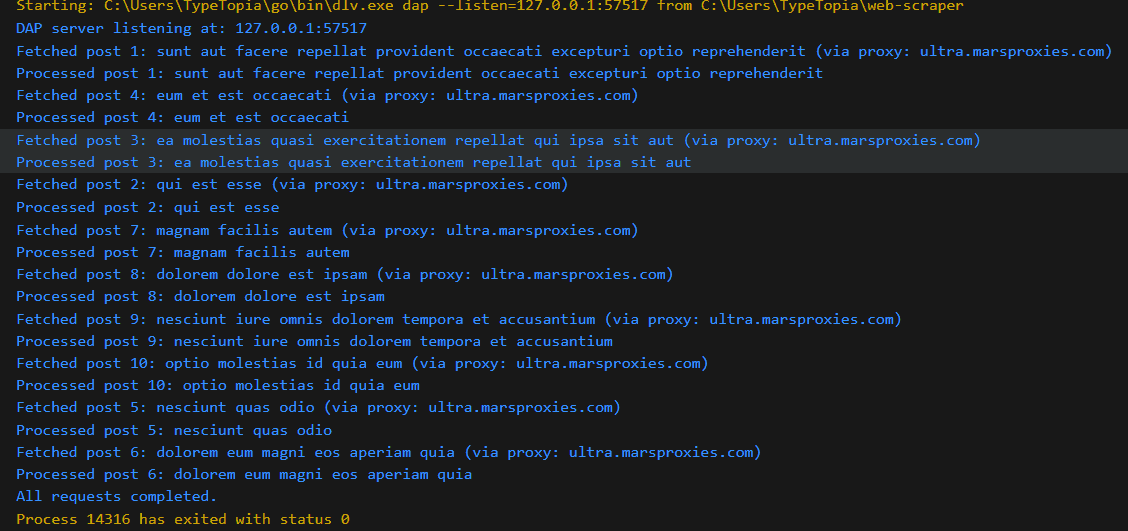
As you can see from the randomized nature of replies, this bot can handle multiple requests at once. But to avoid detection, it waits for two minutes before sending the next request. To enhance memory management, the collected data is stored in a temporary buffer channel.
How to Test and Maintain Your Golang Web Scraper?
You have an upgraded scraper that is capable of evading most detection mechanisms. Even with all the modifications, there are still many opportunities to increase the efficiency of the scraper by catching errors early when websites change their HTML structure and by setting up regular scraping jobs.
Automating Tests for Your Web Scraper
Websites often change their HTML structure, which can disrupt the flow of data scraping. To mitigate this problem, you should set up automated tests to ensure your web scraper is functioning as expected. Below are the different tests available:
- Unit tests: Tests the functionality of individual functions like URL parsing and JSON configuration.
- Integration tests: Confirms the scraper can connect to real or mock websites.
- Mock servers: Using mock HTTP servers to simulate website responses.
Setting up Regular Scraping Jobs (Using Cron Jobs or Task Schedulers)
Other than automating tests, the same can be done for the actual data collection process. For Linux/Mac device users, you can use Cron jobs to schedule your scraper to run at specific intervals. Below is an example:
crontab -e
# Run scraper every day at midnight
0 0 * * * /usr/local/go/bin/go run /path/to/scraper.go
Windows users can use the Task Scheduler to run the scraper at specific times.
Popular Golang Web Scraping Libraries: Comparison and Use Cases
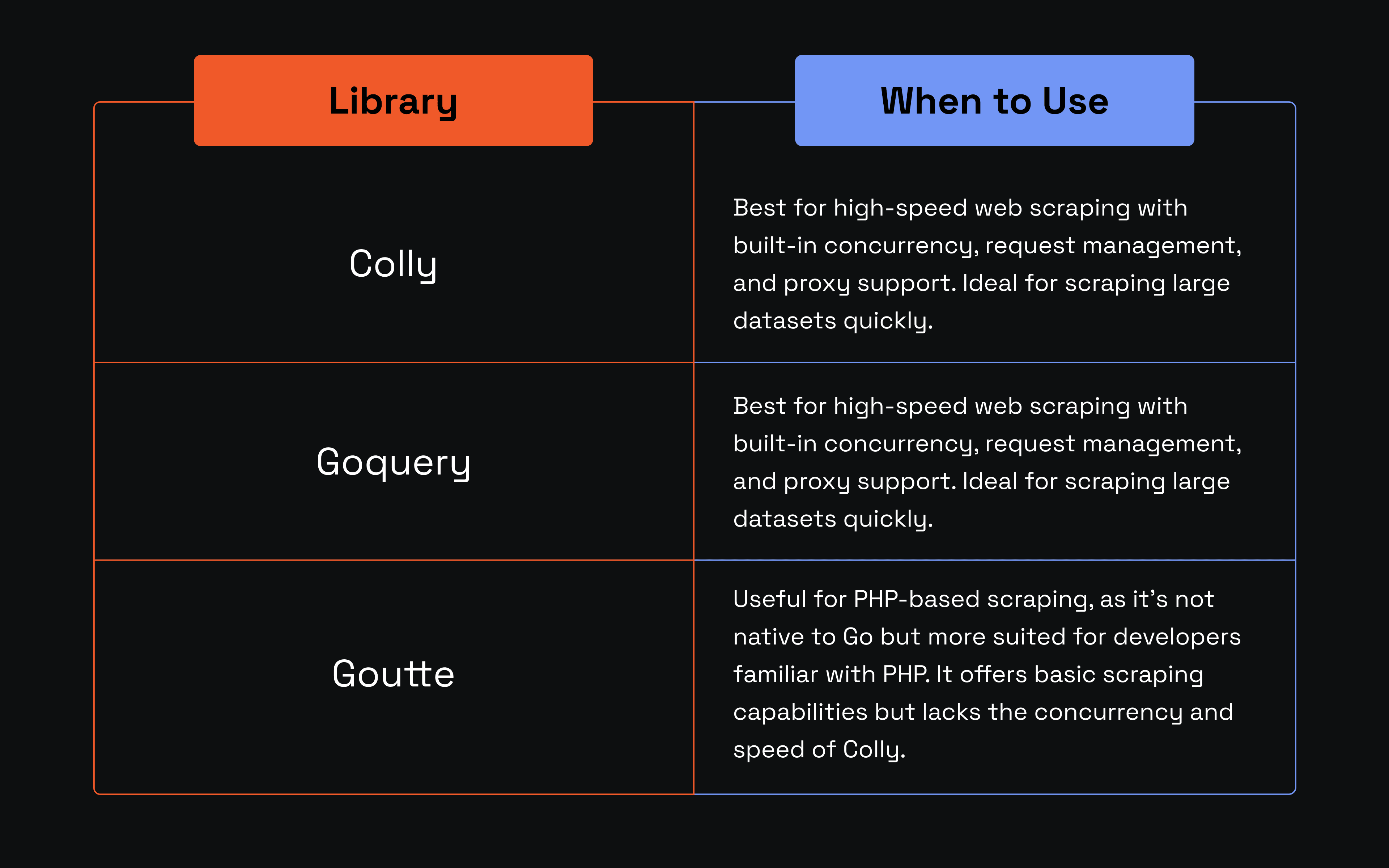
Conclusion
We hope our blog has shed insightful tips on how to create a web scraper in Golang. As you've seen, you can build a simple bot to extract static HTML data, take it up a notch to collect dynamic JavaScript data, and evade detection by rotating proxies.
To enhance the performance of your Go web scraper, you can implement concurrency and parallelism to improve efficiency, rate limiting to avoid detection, and memory management to conserve resources.
Finally, you can implement automated testing and schedule your scraper to collect data at select times without manual interventions. You've also compared the three most popular web scraping libraries and understood when each is ideal. To more data!



