

Data heavily drives contemporary markets, and access to information that provides a competitive advantage is highly valuable. Marketing specialists worldwide revealed to Statista that data-driven strategies proved to be very successful in 32% of use cases, with only 5% failure rates.
Online data encompasses everything from commodity prices, first-hand product reviews, user sentiment, all kinds of news and articles, and anything else you can think of. It can change service development or marketing strategy, but how to efficiently extract data when there's so much of it?
Web scraping is one way of obtaining online information quickly and accurately. Web scraping in Python is often a preferred choice, as this coding language has a beginner-friendly syntax and a variety of tools to extract data from websites.
You can learn more about choosing the right tools for web scraping in our dedicated article. In this blog post, we will provide a Python web scraping tutorial that will get you started.
What Is Web Scraping?
Web scraping is a method of obtaining data from websites automatically. Imagine you are looking for concert tickets to your favorite popular band. But, instead of searching for their shows nearby manually, you have a program that does that for you. On a large scale, web scraping can target multiple websites simultaneously to obtain business intelligence.
Automation is the keyword there. Checking a few concert venues might not take that much time, but what if you had to check tens of thousands? That's the challenge marketing professionals face when collecting data to optimize their campaigns and outperform the competition.
Checking tens of thousands of competitors' sites manually is time-consuming and prone to human error. Instead, tech-savvy specialists extract data using additional tools, like a scraper bot, web scraping libraries, and a rotating residential proxy network to avoid anti-scraping detection.
This way, they can target multiple websites simultaneously or send multiple requests to the same website to get the data faster. Web scraping with Python also allows automating logging in to fetch data that requires human interaction.
However, adhering to data protection laws like GDPR is essential to avoid legal troubles. It's best to refrain from collecting data that is protected by national and international laws and remain respectful of website owners' rules, which are generally outlined in the robot.txt document. But before we go into web scraping in Python programming language specifics, let's overview its main use cases.
Common Use Cases
Numerous industries that rely on data-driven decision making use web scraping to obtain information. Here are 4 use cases where you can often encounter data extraction using this method.
E-Commerce Price Comparison
E-commerce companies use web scraping to retrieve product prices from retail sites. They use this data to compare prices and set theirs accordingly, but also to monitor commodity price changes, spot time-sensitive discounts, and keep the dataset updated.
In this case, Python programming language is beneficial by supporting advanced web scraping features mandatory for accurate data extraction. Retail sites often block scrapers to keep their websites up and fast and protect user data from unethical mining. Python requests can be tailored to avoid interfering with the website's functioning and target only parts allowed by the robot.txt file.
However, if you adhere to transparent and ethical web scraping practices and respect the website's rules, you can extract data quickly while eliminating human error at the same time. Using a Python library like Beautiful Soup parses extracted pricing data to make it more readable and ready for further analysis.
Market Research and Competitor Analysis
An exhaustive market research requires a lot of data. Nowadays, that data is also widespread across review and retail sites, social media, forums, competitors, and news sites. Obviously, businesses can do without such information, but they leave it to the competitors, which will enhance their marketing strategies to draw more clients.
Web scraping with Python lets businesses scrape competitors' websites and, combined with proxies, avoid anti-scraping protection. For example, SEO specialists scrape competitors' news sites and blog articles to extract keywords they are ranking for. This way, content managers can identify keyword gaps and optimize their website so that Google ranks it higher, increasing organic traffic.
Social Media Data Gathering and Sentiment Analysis
In 2025, there are over 5 billion social media users, the majority of people who have internet access. Social networks are the go-to platforms to familiarize with public opinion and notice consumer trends and sentiment. Even little things like likes and shares can provide insight into what consumers admire and what's not that well received.
Scraping publicly available social media data is legal, but mining personally identifiable information (PII) is typically not. Companies that use such data as a business model must meet strict security regulations, like keeping PII gathering to the minimum, encrypting data at rest and in transit, and deleting it after it's no longer needed.
It's also worth mentioning that many social media platforms offer an Application Programming Interface (API) to streamline data exchange. It regulates how two consenting parties share specific information but is also more restricted compared to web scraping.
Building Datasets for Machine Learning
Web scraping in Python language is an efficient method to gather, parse, and then use extracted data for machine learning (ML). Before starting, it's essential to clearly define the required data to avoid stuffing machine learning algorithms with irrelevant variables. Simultaneously, ML requires large datasets, so it's best to estimate possible volume and pick web scraping tools that are scalable.
Once again, ensuring the legality of scraping data for ML is paramount to avoid possible troubles. Meta, a company that's no stranger to data harvesting, recently got into legal trouble for pirating 82 terabytes of books for its AI training. It is always best to adhere to data privacy and copyright laws before scraping large volumes of information.
Setting Up Your Python Environment
First things first, you should download Python from its official website. We recommend using any 3.x version, and this Python web scraping tutorial was written using the 3.13.2 version for Windows. Before installation, make sure to check the "Add Python to PATH" box, which allows you to execute Python from the command prompt or terminal.

We recommend creating a virtual environment after successful installation. Even if you're a beginner, you will likely expand Python with more than a few web scraping libraries to streamline HTTP requests or mimic actual user behavior. Using separate virtual environments ensures that your scraping projects do not overlap and Python libraries do not conflict with one another. Open the Command Prompt or terminal and use the following code:
python -m venv scrapingVE
This will create a virtual environment with the name scrapingVE. Don't be surprised if you do not get a Command Prompt response, as it will not confirm successful setup. To verify, check the directory where you executed a command. On my device, I can find a newly created scrapingVE folder.
Lastly, install preferred tools to ease up the development process. Choose an integrated development environment (IDE), like Visual Studio Code or PyCharm, that's specifically designed for Python. However, this example uses the standard Python environment to avoid any confusion due to IDE differences.
For this guide, we will also use 3 additional libraries: Requests, BeautifulSoup, and Selenium. Although Python offers many, many more tools for scraping data, these 3 are widely used and optimize key development processes. Let's explain each Python library in more detail.
Essential Python Libraries for Web Scraping
Although Python is fully capable of executing web scraping tasks on its own, most of the time, you will use web scraping libraries. For example, Beautiful Soup and Requests are almost always used to streamline HTTP requests and parse HTML content. Let's start with Requests.
Requests – HTTP Requests
HTTP requests are a fundamental part of clients' communication with websites. In a very simplified version, web scraping is sending HTTP requests to websites asking to fetch some information. However, it becomes much more complex when scraping multiple websites simultaneously, scraping complex JavaScript-heavy websites, or mimicking a real user.
The Requests library is almost always used to streamline this process. It simplifies HTTP requests like GET, PUT, and POST by taking care of lower-level networking complexities. The Requests library automates encoding and decoding, handles status code responses, stores cookies, and even verifies SSL certificates for security.
Installing Requests, as well as other Python libraries for web scraping, is easy. Go to the commander prompt and use the following code:
pip install requests
If successful, the command prompt will not write anything back (it may take some time to get used to for new users.) Now, open your IDE (in this example, the standard Python environment) and write the following:
import requests
If you want to verify whether the Requests library was successfully imported, use this code:
print(requests.__version__)
Notice that there are two double-underscores before and after "version" (_ _ just without space between them), which might not be visible on some documents. You should see something familiar to this if there are no issues.

Above, Python informs that we are using the 2.32.3 Requests library version. Now, let's see this library in action and send a GET HTTP request, which is at the core of web scraping. Below are six lines of the most straightforward Python web scraping code to get you started.
url = "https://marsproxies.com/"
response = requests.get(url)
response.raise_for_status()
print(response.status_code)
print(response.text)
In the first line, we specify the website that we will be scraping; feel free to change MarsProxies.com to your preferred option. Then we send a GET request, but we also want Python to verify whether the connection was established successfully and print the status code. Lastly, we instruct Python to return the response (in this case, an HTML document) as a string. This is what we get.
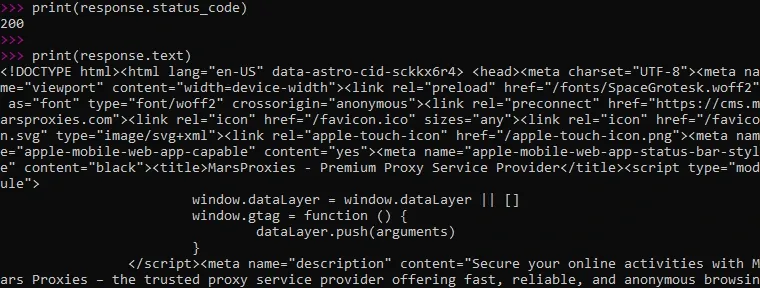
Firstly, Python returns the status code 200, which indicates that the HTTP request was successful. Below, we order Python to fetch the content of the website, and on the 5th line, we can see the !DOCTYPE html, so the response comes as an HTML document in a string format.
Then, we can see the unparsed website code. The code goes for hundreds of lines so extracting data from it manually is tedious and will likely include errors. That's why, similarly to requests, Beautiful Soup is also almost always used to parse data and make it readable.
Beautiful Soup – HTML Parsing
Dealing with unparsed data is inefficient and time consuming, which does not align with web scraping goals. Beautiful Soup is the most popular Python library to parse HTML and XML documents.
This tool allows you to navigate the HTML tree and look up data using attributes, tag names, and CSS selectors. It automates this process, achieving within minutes what may otherwise take days. Let's install Beautiful Soup and see it in action.
Firstly, open the terminal or command prompt and install the library using the following line:
pip install beautifulsoup4
Then, go to your Python IDE and import Beautiful Soup library using this command:
From bs4 import BeautifulSoup
For better visibility, we will use a very simple HTML code and instruct BeautifulSoup to find its h1 elements. Start by defining HTML content in Python:
html_content = """
Then, write a straightforward website HTML code using the example below:
<!DOCTYPE html>
<html>
<head>
<title>Example page</title>
</head>
<body>
<h1>The first h1 tag</h1>
<h1>A second h1 tag</h1>
<p>Some more content</p>
<ul>
<li>Item example</li>
</ul>
<a href="https://www.example.com">Link to Example</a>
</body>
</html>
"""
We have created a simple HTML code that has 2 h1 tags, a paragraph, a list item, and a random backlink. We want Beautiful Soup to find all h1 tags. Here's how:
soup = BeautifulSoup(html_content, "html.parser")
h1_tags = soup.find_all("h1")
for h1 in h1_tags:
print(f"H1 tag text: {h1.text}")
Firstly, we create a Beautiful Soup object and set a variable that we will be parsing HTML content. As you have seen in the previous example, the Requests library is an efficient way to extract website HTML content, so these two tools go hand in hand very well. Here's what we got:
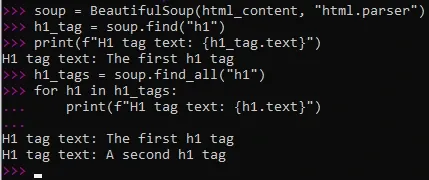
As you can see, we have written two functions: the soup.find("h1") and soup.find_all("h1"). We want to demonstrate the specifics of Beautiful Soup. The first function goes over the HTML code and only returns the very first h1 tag it encounters, so even though we have 2 h1 tags in the code, it only returns the first one as a text.
Things get a bit more complicated to find both of them. In this case, we can use the h1_tags variable and instruct Python to print the text for each h1 tag it can find in the code. As you can see, now it returns two texts and we have successfully parsed a simple document.
Selenium – Handling JavaScript-Heavy Websites
In the previous example, we have used static HTML code that is easy to scrape and parse. However, you will be dealing with much more complex websites most of the time, which include dynamic JavaScript elements.
Selenium is an excellent Python library optimized for dealing with JavaScript-heavy websites. It waits until the website loads fully before fetching the requested data to make sure the dataset is complete. It is also capable of browser automation and can perform clicks, submit forms, and imitate scrolling, making it a very useful tool for web scraping.
Firstly, install Selenium from the commander prompt, as we've done previously with other libraries. This is the code line:
pip install selenium
You also have to download the web driver manager for Selenium using the following code for Python version 3.x:
pip3 install webdriver-manager
Afterward, import Selenium in Python. If you get any ModuleNotFoundError messages, make sure that you are installing libraries in the virtual environment you have created previously. Type the following in Python:
import selenium
Simple. Now, there's a lot you can achieve with Selenium used as a headless browser, but it all starts with opening a website. Let's use the simplest way to open MarsProxies.com with Selenium code lines. Free free to use the following:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
webdriver.get("https://www.marsproxies.com")
Selenium has just opened the MarsProxies website in Chrome browser, which is being controlled by automation software, as seen in the image below.
Now, you can inspect the website structure and use Selenium commands to extract data. For example, commands like driver.find_element(By.CSS_SELECTOR, "css_selector") lets you find data using CSS selectors. You can also look it up by name, class name, ID, and other criteria that are used in your chosen website structure.
Understanding Website Structures
We have overviewed the general Python installation process, setting up an environment for scraping and development, and the setup of 3 extremely popular Python libraries for web scraping. However, you will not get far if you do not understand the website structure.
After all, scraping HTML content and dynamic websites requires more knowledge outside of Python. For example, JavaScript know-how helps you utilize Selenium to the maximum, and fetching data using various selectors is much easier if you know how websites are structured.
Basics of HTML and the Document Object Model (DOM)
HTML stands for HyperText Markup Language and forms the core of websites. Imagine a human body, so the HTML would be the bones that everything else is built around. You have already seen a basic HTML code when we used Beautiful Soup to parse it and extract 2two h1 tags content.
Although our example was very straightforward, HTML code is generally easy to read and understand. Things get more challenging the more functions the website has, such as CSS elements for its design and JavaScript code to make it dynamic and interactive.
Also, consider that you will encounter websites that use various JavaScript libraries. For example, ReactJS, developed by Facebook (currently Meta), is popular among front-end developers because it encourages coding reusable components and uses a virtual DOM to improve performance. However, it also adds complexities, like working around the unique JSX syntax extension.
So, starting from HTML, you will encounter more and more complex elements. HTML content is formed around tags like <p>, <h1>, <div>. For example,
<p> this is a paragraph example </p>
Notice that each tag has a closing tag that begins with /. Suppose you want to scrape prices from a retail website. In this case, you will have to identify which tags store pricing data and target them using Python requests.
Here's an example of a very straightforward HTML code:
<!DOCTYPE html>
<html>
<head>
<title>Example HTML</title>
</head>
<body>
<h1>First header</h1>
<p>Paragraph element</p>
<ul>
<li>First item</li>
<li>Second Item</li>
</ul>
<a href="https://www.MarsProxies.com">Link</a>
</body>
</html>
The first line declares the document type, in this case, HTML. Then we have a <head> tag, which includes the document's metadata (links to stylesheets, title, etc.)
The most crucial part is written between the <body> tag and the </body> closing tag. The code written here is the main website's content. Our example has a header, a paragraph, two items, and a backlink. You can imagine that pricing details would be included as <li> elements with a specific class or CSS selector, which you could then use to scrape prices using the discussed tools.
DOM stands for Document Object Model. It is a programming interface for XML and HTML documents. It represents these documents in a tree-like structure of objects, where each object stands for some part of the document. Web scraping tools interact with the DOM representation of HTML and XML documents because they are easier and faster to navigate.
The HTML document is formatted as a collection of nodes in the DOM tree-like structure. Here are a few different types of nodes:
- Attribute nodes (class, ID, href, etc.)
- Text nodes represent the text in HTML elements
- Element nodes, such as paragraphs and divisions (<p>, <div>, <a>, etc)
It's worth noting that the DOM structure is hierarchical. There are parent nodes that have child nodes below them, which, in turn, have sibling nodes that share the same parents. Tools like JavaScript and Selenium work with the DOM representation to interact with the content efficiently, whether adding elements to it or fetching specific information.
How to Inspect Elements Using Browser Developer Tools
Understanding a website's structure is a solid first step in your web scraping with Python journey. However, where do you find HTML content? Luckily, inspecting the website's codebase is very easy. You can use browser developers' tools that will open a window to your right that has tons of valuable information, including HTML code.
On Windows, you can open the developer tools by pressing ctrl + shift + j. Mac users should go to the Safari settings advanced section and enable the "Show features for web developers" option. Then, pick a website you're going to use as an example (we will continue using MarsProxies.com as ours), open it, and then press this combination. Notice a new window opened on the right side of the screen - these are the developer tools.
Developer tools display a lot of information, like network activities, performance, status updates, and security information like SSL certificate verification. For this article, the Elements section is the most important part, so click on it. Here's what we see in our example:
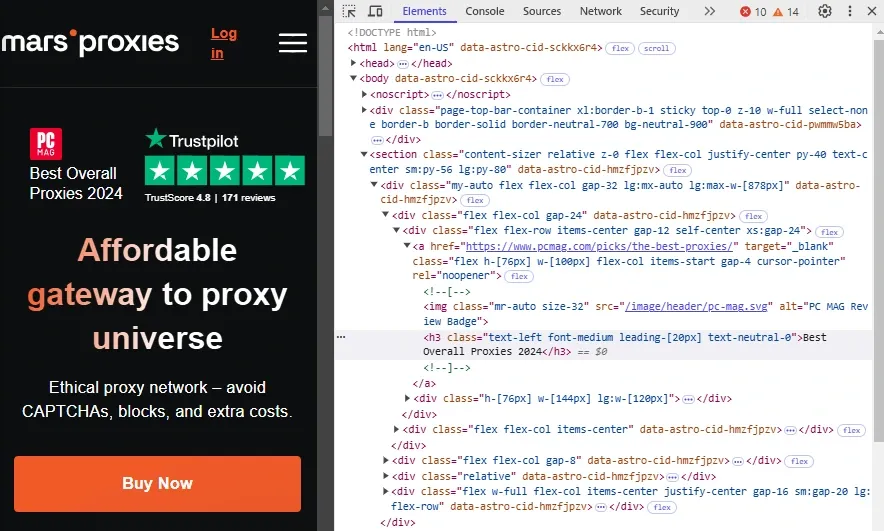
Notice the h3 element selection in the image below. It has class a few class attributes like "font-medium" and "text-neutral-0", which you can use to scrape all elements with the same class. Or you can target all h3 elements, depending on your demands and website layout.
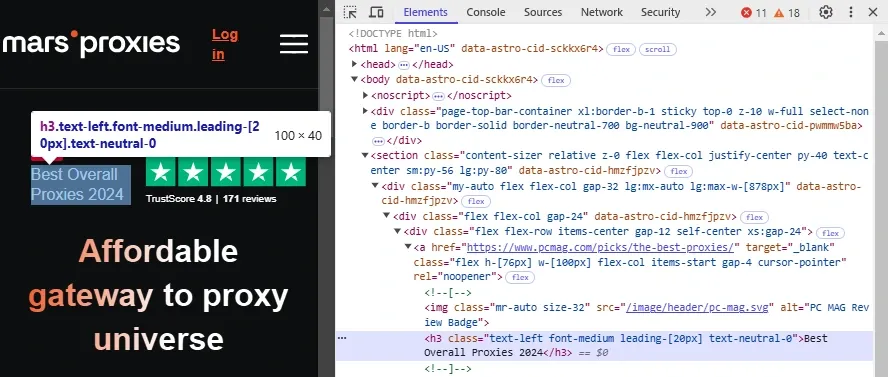
Lastly, inspecting a specific element is very useful to get information about it. You can right-click on the chosen element and click Inspect from the dropdown menu.
For example, we clicked on the "Best Overall Proxies 2024" text, and it immediately opened the developer tools at the right place. This way, you can select the required elements without going over the lengthy HTML code to find them manually. Armed with this information you can proceed with your scraper using various selectors, like class, attribute, CSS, and more.
Web Scraping Basics With Python
Now, you have sufficient information to start scraping data at a basic level. Also, keep in mind that although there are experienced web scraping professionals, it is a relatively new method of gathering online data.
Many scraping specialists started by analyzing HTML content using developers' tools and then picked additional knowledge along the way, which is an excellent way of learning! Let's overview the essential Python web scraping aspects again to remember the most important details. Here is a general web scraping workflow:
Select Data and Website
Firstly, define what data you need to fulfill your goals. Then, identify a website that has that information. At this stage, verify that collecting that information is perfectly legal and that you adhere to the website's scraping rules—more about it in the Ethical Practices in Web Scraping section.
Inspect HTML Code
Start by inspecting the website's elements. Right-click on the chosen element and choose Inspect from the dropdown menu. Check element tags, classes, and attributes so that you can use them for scraping later on.
Gather Tools
Now that you know what kind of website you're dealing with, you can pick the required tools. We recommend installing the Requests library for everybody, as it streamlines one of the essential data scraping processes, which is sending HTTP requests.
Use Beautiful Soup if you're scraping static HTML content and want to parse it efficiently. However, if you're dealing with a dynamic and JavaScript-rich website, consider using Selenium. At this stage, also prepare your IDE, proxies, and all other tools you plan on using.
Develop Code
Now, you can start writing code to scrape data. In this article, we have already outlined the basic Python code to get you started, but you will learn many more functions quickly. At first glance, it may seem overwhelming, but keep pushing for the breakthrough, which comes with time, patience, and effort. The more advanced Python web scraping code you learn, the more challenging sources you can target.
Store Data
When you have gathered the required information, you have to store it somewhere. Most scrapers have built-in tools to store information in CSV, JSON, and XML formats. Select your desired format and save scraped data. Keep in mind that scraping personally identifiable information requires encryption to protect it against data leaks.
Parsing HTML Content
Collecting information is the most significant part, but a successful scraping campaign generally involves data parsing. Data parsing converts information from one format into a more structured one so that it is usable for other computer programs and readable to the human eye.
Recall the image earlier in this article where we sent a GET HTTP request to MarsProxies.com. It fetched the HTML content as a string, which went for hundreds of lines, and making sense of it is extremely hard. When scraping, we recommend specifying data requirements as narrowly as possible and then parsing it with libraries like Beautiful Soup.
Using Beautiful Soup for HTML Parsing
If you continue learning Python web scraping, then you will likely have to learn Beautiful Soup as well. Use the concise guide we have outlined previously to install it and parse the required elements from the whole HTML content.
Beautiful Soup removes HTML complexities and simplifies working with HTML and XML documents. Simultaneously, it allows searching such documents using its data lookup functions, like select() and find_all().
Navigating the Dom to Find Elements
After gaining some scraping experience, you will often encounter DOM "trees" instead of complex HTML files. Once again, Beautiful Soup is invaluable here to parse an HTML code into a readable DOM-tree structure. Then, you can use code like "h1 = soup.h1" to fetch the first h1 tag or "paragraph = soup.find("p", class_="example")" to grab the first <p> element with an "example" class.
When working with DOM you can also use its selectors, like .parent, .children, .previous_siblin, and more. This expands data lookup customization options and lets you scrape documents faster and more efficiently.
Extracting Text, Links, and Images
You can use Python to extract links and elements alongside text. However, when extracting visual material, always remember to adhere to copyright laws. Scraping copyrighted material is illegal, especially if it is then being reused for business goals. However, once you've got the legalities sorted out, here's an example of image scraping using Python.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install())) driver.get("https://www.marsproxies.com")
images = driver.find_elements(By.TAG_NAME, "img")
for image in images:
src = image.get_attribute("src")
alt = image.get_attribute("alt")
if src:
print(f"Image: {src}, Alt: {alt}")
Keep in mind that Python's code must meet the required indentations, but it will also intuitively follow the indentation logic itself or outline it in the errors. In this example, after pressing Enter, we got these results:
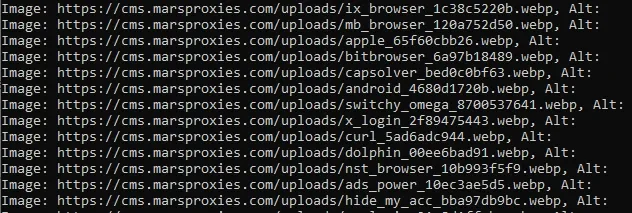
Here, Python grabbed the URLs of all images it found on our landing page (this image is but a fraction of the whole dataset.) Now that we have the addresses of each image, we can download them with a web scraper.
Once again, this is just an example, and before scraping any visual material, make sure it is legal and abides by copyright laws.
Handling JavaScript-Rendered Content
An accurate and complete dataset is one of the most important web scraping aspects. After all, what's the point of having information if you cannot rely on it fully? That's why it's essential to master a tool that can handle JavaScript-loaded content.
JavaScript makes websites dynamic and interactive, so it is used practically everywhere. If you scrape JavaScript-heavy websites using, for example, only the Requests library, it will fetch the HTML content but will not include elements that were loaded by JavaScript afterward.
Once again, we recommend familiarizing yourself with Selenium to scrape JavaScript websites efficiently. The Selenium WebDriver Python library automates a genuine browser and actually loads the page fully so that all JavaScript elements are rendered.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://www.marsproxies.com")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.TAG_NAME, "img"))
)
images = driver.find_elements(By.TAG_NAME, "img")
for image in images:
src = image.get_attribute("src")
alt = image.get_attribute("alt")
if src:
alt_text = alt if alt else "No alt text provided"
print(f"Image: {src}, Alt: {alt_text}")
This example also aims to extract images from our website using a similar Selenium code from the previous example. However, we added an additional WebDriverWait(driver, 10) function. This small additional is essential for scraping JavaScript-heavy websites because it tells Selenium to wait up to 10 seconds for at least 1 image to load fully.
This way, the library ensures that JavaScript has enough time to render all elements. Only then does it fetch the data to make the collection complete and accurate.
Configuring Selenium for Advanced Web Scraping
Do you feel ready to go further and try out some advanced tricks? Below, we have briefly outlined a few advanced Selenium features, but elaborating on this topic entirely is a task for another article.
Set a Wait Limit
We have already covered the WebDriverWait(driver, x) function, but it is very important to remember to set a wait limit. One of the key Selenium features is fetching JavaScript-rendered elements, and the wait function ensures you won't miss anything important.
Customizing User Agents
User agents are strings of text that store information about the user and their web browser. Web scraping often requires switching between multiple user agents because using the same one for data gathering may result in access restrictions, even if the user is using web proxies for anonymity.
Selenium offers tools to change user agents. Use the following code lines:
options = webdriver.ChromeOptions() options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
In this example, we use a user agent for Chrome version 114, and you can find more user agent strings for other browsers with a quick Google search.
Adding Proxies
Proxies are invaluable for advanced scraping tasks because they allow targeting multiple websites without risking detection. Here's how to configure proxies with Selenium commands:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://your_proxy_address:port")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
We also recommend checking out rotating residential proxies if you aim to scrape without exposing your original IP address.
Running Headless Browsers for Efficiency
Once you learn the basics of web scraping, you can try out using Selenium as a headless browser. Such a browser is just like a regular browser but it does not have a GUI, so you will control it using Selenium commands. Here's how to set it up:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--headless=new")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get("https://www.marsproxies.com")
print(driver.title)
driver.quit()
This browser type for web scraping has several advantages. Firstly, it's more resource-friendly and doesn't consume as much memory and CPU power. Because it doesn't use a GUI, it also works faster than a traditional browser. Lastly, once you master advanced Selenium functions, you can automate a headless browser to scrape large volumes of data and scale your operations.
Ethical Practices in Web Scraping
Due to a few unfortunate web scraping misuse cases, this practice has been given a bad name in some circles. It is crucial to understand that web scraping is just a method of obtaining data automatically.
As with all tools it can be used for good or for the illegal, so make sure you follow ethical web scraping practices before collecting information from websites.
Understanding and Respecting robots.txt
Most websites use a robot.txt file that informs web crawlers (and scraper bots) of accessible website parts. You can freely collect information where it's allowed, but web scraping where it's restricted can draw attention and, sometimes, cause severe legal issues.
Robots.txt is generally located in the root directly, like https://www.MarsProxies.com/robots.txt. What's more, Python has dedicated functions to fetch and parse the robots.txt file so that you can clearly see what's allowed.
Implementing Delays and Random Intervals Between Requests
You risk slowing the website down or even overloading it if you send too many web scraping requests too fast. Firstly, it negatively impacts website performance, so its owners may take action to block you. However, even if you don't slow the website down you can still get banned by anti-scraping algorithms.
Instead, configure your web scraper to include delays and random web scraping intervals. This way, your requests will imitate an actual human user and won't draw negative attention.
How to Avoid Detection in Python Web Scraping
Businesses and website owners often restrict web scraping bots but, in reality, scrape competitors themselves. For example, Amazon has robust anti-scraping protection systems, but it also scrapes the web in large volumes to stay ahead of the competition.
Here are a few tricks to avoid detection in Python web scraping.
Strategies to Prevent IP Bans
Here's what you can do to avoid IP bans while scraping. Firstly, consider using proxy servers. Proxies mask the original user IP address and substitute it with an alternative so that websites cannot identify the same user behind scraping requests that come from different IPs.
Even if your proxy IP gets blocked one way or another, you can simply connect to a different one and continue with the task. We recommend rotating residential proxies for web scraping because they offer robust online privacy protection features and regularly change the IP address to avoid detection.
Additionally, consider switching user agents so that your data-gathering requests look like they are coming from different genuine browsers. Also, set a delay and rate limit to avoid drawing attention to your scraper bot and make it resemble more human-like behavior.
Lastly, we want to remind you to always adhere to national data safety laws and international regulations like GDPR, CCPA, and HIPAA and never use web scraping or proxies to hide criminal activities. Law enforcement has sufficient resources to track users online. Web scraping is primarily a data collection and analysis tool widely used in data science and should remain within legal boundaries.
Conclusion
If you've made it this far, then you have successfully set up a Python environment to begin web scraping. Whether you already have some experience and want to deepen your knowledge or are just starting, we recommend learning Requests and Beautiful Soup libraries from the get-go.
We also recommend creating a virtual environment for separate scraping with Python projects. This way, the libraries that you use will not conflict with one another due to version differences, and you can control each project more efficiently.
The best way to go from here is by working on a real project. Simply come up with a web scraping idea, like extracting video game discounts from e-shops or automating a login function using Selenium. Although we have outlined the general Python code to get you started, it will differ depending on the circumstances almost all the time.
Lastly, we want to remind you to be particularly mindful about data security laws. Refrain from gathering personally identifiable data whenever possible, and do not scrape copyrighted material, as it will get you in legal trouble. Otherwise, web scraping specialists are in high demand and may land you lucrative career positions.


