

The amount of data generated online has increased and skyrocketed during the last decade. Statista predicts that by 2025, global online data creation will surpass 181 zettabytes. This data explosion is a challenge that contemporary businesses are struggling with, as reported by Forbes, particularly in capturing and analyzing visual information, including video ads, photo assets, user-generated content, etc.
This increased the demand for web scraping tools that excel at extracting data from online websites. Imagine web scraping as your virtual assistant, looking for relevant information for you.
Web scraping, also called online data extraction or simply online data collection, is a process of gathering information from online websites. It often involves a web scraper and uses proxy servers to scrape multiple websites simultaneously. The collected data is usually stored in formats ready for further analysis, like XML, JSON, and CSV.

Web scrapers are automatic tools for extracting data from websites and publicly available online documents. Their importance cannot be understated because they can gather information within hours, which would take weeks, if not months, manually. Simultaneously, Web scrapers eliminate human error, increasing data reliability and quality.
Before we discuss efficient web scraping software and the most popular web scraping techniques, let's overview its most common use cases.
Market research
Businesses utilize web scraping to get and compare commodity prices, analyze user reviews, and monitor competitor's marketing strategies.
Academic research
Scientists scrape data to save time and obtain more information for scientific study. For example, healthcare scientists scrape public health data to gain better insights into widespread illnesses.
News sites
News sites can extract data from publicly available domains that agree to share it and then use it on their websites to attract more traffic, like weather forecasting agencies.
Personal projects
Suppose you're looking for affordable rent options. Instead of manually going through dozens of renting websites, you can scrape them to get options according to your requirements.
Human resources
HR specialists collect data from online employment agencies or social networks, like LinkedIn, to get the best employee profiles that would suit their needs.
Understanding Web Scraping: Ethics and Legality
As you can see, web scraping has multiple use cases. That's why your scraping process and scraping tools significantly depend on what you use it for. Getting data from websites that use static HTML code is different from extracting data from dynamic and interactive ones.
Web scraping techniques are instructions for searching, identifying, and collecting data. Whenever you go online to look for product prices, like plane tickets, write them down, and then repeat it elsewhere for a comparison, you participate in manual web scraping. However, it's worth pointing out that web scraping is usually reserved only for automatic scraping techniques, as it is the main selling point.
It's also worth noting that web scraping is a touchy subject due to several misuses. The Cambridge Analytica scandal, in which it illegally scraped 87 million Facebook profiles, caused long-lasting damage to the web scraping industry. That's why it's best to review web scraping legality and ethics before starting.
It is generally agreed upon that collecting personally identifiable information (PII) is a bad idea. Real people's names, phone numbers, addresses, employment details, etc., are private PII units, even if they are posted on publicly available forums or social networks. In Europe, the General Data Protection Regulation (GDPR) safeguards such information from misuse. You must review GDPR if your business model relies on such information, and you will have to use encryption to store it.
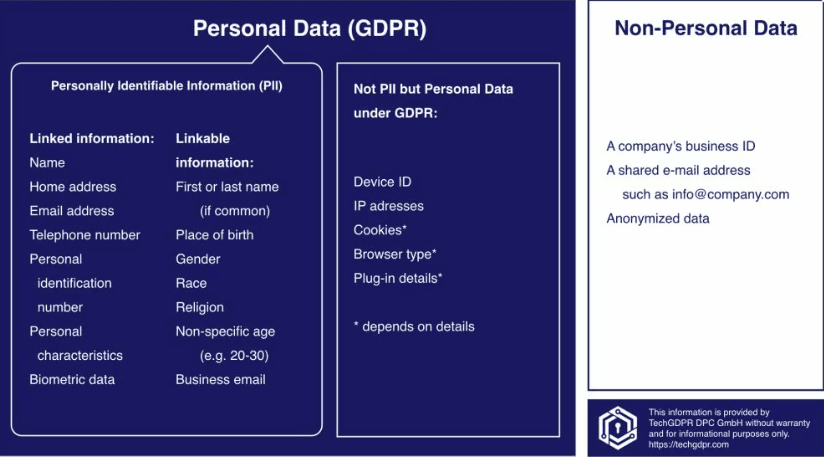
Be mindful of copyright restrictions. You must ensure that the website agrees to share data like pictures and videos. For example, scraping photo assets and then reusing them without obtaining permission can result in a costly lawsuit. You can find copyright information in the Terms and Conditions and Robot.txt documents.
Lastly, be respectful towards website owners. Scraping password-protected data from websites can be a privacy violation. Simultaneously, do not overload the website with too many concurrent requests, but inspect the boundaries outlined in the Robot.txt file.
Web Scraping Key Terminology
Before we explore web scraping tools and popular scraping techniques, it's essential to grasp the key terminology. This knowledge will not only help you understand website structure but also guide you in selecting the most appropriate scraping tool for your needs.
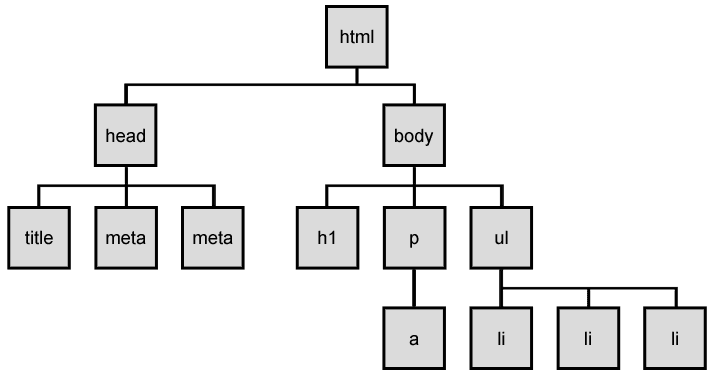
HTML, or Hyper Text Markup Language, is a fundamental basis of websites. It's a language that structures the main content you see on a webpage, including elements like paragraphs, headers, backlinks, videos, etc. For instance, if you're scraping a car-selling website that uses HTML to organize pricing elements, you'll need a web scraping tool designed for HTML scraping.
However, HTML websites are limited and may not capture modern visitors' attention, so you'll often encounter DOM trees. DOM, or Document Object Model, acts as a bridge between HTML and programming languages like JavaScript. JavaScript is used to add dynamic elements to websites, such as flashy ad pop-ups and dropdown menus.
Whenever a web browser loads a website, it creates a DOM document that lists all elements, including headings, images, etc. Scraping DOM trees is called DOM parsing, and it allows for more structured data collection but also requires more in-depth HTML knowledge. Luckily, there are tools like Beautiful Soup to help with that.
You don't have to rely solely on web scraping to get the required data. An API is an excellent alternative to web scraping. API stands for Application Programming Interface, and it regulates information exchange between two consenting parties. For example, your news site wants to use weather forecast data from an agency. Because this is mutually beneficial, they may have a public API you can use to extract data.
This brings us to the last term: bot detection system. Many websites prefer to avoid being scraped because they consider it uncompetitive behavior or an unnecessary resource drain. In reality, most businesses that deal with online data participate in web scraping. However, this results in anti-bot features like CAPTCHAs, IP bans, or honeypots.
Whenever you use a web scraping tool to collect data from websites, it sends data collection requests using your original IP address. This way, websites can mark it down and block it. Instead, we recommend using web scraping tools that are compatible with rotating residential proxies. This way, your scraping process will benefit from an additional layer of privacy, and you can switch to a new IP whenever you get blocked.
Tools and Technologies for Web Scraping
You don't have to be a coder to scrape data, but knowing a programming language will significantly expand your options for web scraping techniques. You can build your own web scrapers or select the scraped data format you require. Those willing to go through this more challenging but highly rewarding path should start with Python for data scraping techniques application.
Python
Python is one of the most widely used programming languages out there. It is also readable and easy to learn. Furthermore, it has excellent web scraping libraries and frameworks that are optimized for different needs. Python is open-sourced, so you can always join its online community for assistance. BeautifulSoup and Scrapy are two Python web scraping tools that can take it to a higher level.
JavaScript plus Node.js
Like Python, JavaScript is just as widespread, if not more. For a long time, it was reserved for front-end tasks to create online websites, so, naturally, it is very applicable for scraping data. But we must warn you that you will require advanced knowledge to benefit fully from JavaScript scraping tools. That's because it uses the Node.js runtime environment to allow backend server-side scripting. Puppeteer is a Node.js library suited for scraping dynamic websites that requires some tech know-how.
R
Gathering online data is just as important as visualizing it. After all, vast scraped data sets are used for further analysis to present the results in an understandable, easily interpretable manner. That's where the R programming language jumps in. R is optimized to target large data repositories. Furthermore, it has built-in visualization features that streamline data analysis. Although R has complex language syntax, it also offers valuable tools, like rvest.
Popular Web Scraping Libraries and Frameworks
We recommend learning an additional web scraping tool as soon as you feel comfortable with the chosen programming language. Here are four options often used to streamline data extraction.
BeautifulSoup
BeautifulSoup, a Python parsing library, is designed for easy retrieval of information from XML and HTML files. It boasts a user-friendly interface, built-in error handling, efficient information lookup options, and cross-platform support. Here's a simple code snippet that demonstrates how BeautifulSoup locates <h1> HTML elements.
from bs4 import BeautifulSoup
# Sample HTML content
html_content = """
<h1>This is a heading</h1>
<p>This is a paragraph with some text.</p>
"""
# Parse the HTML
soup = BeautifulSoup(html_content, 'html.parser')
# Find the heading element
heading = soup.find('h1')
# Extract and print the text content of the heading
print(heading.text)
In Python, the # stands for a comment tag. As you can see, the actual code is close to simple English syntax, which is why it is so popular among web scraping professionals.
Scrapy
The Scrapy Python framework was created to enhance web scraping using Spiders (web crawlers), parsers (data extractors in the required format), and built-in item pipeline options for data storage and movement. Scrapy is fast and highly customizable, but it is also hard to learn and underperforms regarding JavaScript websites. Once again, the open-sourced code provides numerous options for seeking help online.
Puppeteer
Puppeteer is a Node.js library that is one of the best choices for scraping dynamic websites. It utilizes headless browsers that run in the background without an interface to automate browser interactions. Puppeteer is capable of following URLs, filling out forms, clicking buttons, and more. It is among the best web scraping tools to mimic organic user behavior.
rvest
rvest is very useful for web scraping using the R programming language. Because R is somewhat complex, rvest simplifies website downloads and allows targeting specific HTML elements or using CSS selectors to narrow down the search scope. The downside is that rvest lacks advanced customization options, which is a fair price for its simplicity.
Web Scraping Techniques
You've got your tools up and running and feel ready to scrape data from a website. However, as mentioned previously, website structures differ significantly. Follow our tips below to pick the correct web scraping techniques and tools.
Simple HTML Parsing
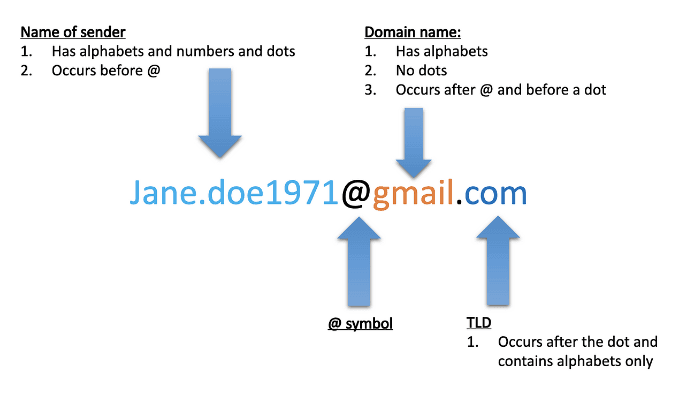
This is among the most straightforward web scraping options, and you can learn it in no time. You will use regular expressions to identify patterns within static HTML documents. For example, you can instruct your web scraper to target "[email protected]" elements to scrape emails. The same applies to product prices, descriptions, etc. However, this method is unsuited for more complex HTML websites.
The BeautifulSoup Python library is a great tool for optimizing Simple HTML parsing. It has a tree-like structure with a hierarchical representation of elements and easy lookup tools. BeautifulSoup lets you search by attributes, tag names, and CSS selectors.
Browser Automation and Headless Browsers
As the name indicates, this web scraping method uses a web browser, usually a headless one, to simulate organic user behavior. For example, if there are elements that require a specific action to appear, like a button click, you can use this method for scraping data, which is reserved for human visitors. Once again, we remind you to consider legal and ethical implications to avoid risky situations like scraping personally identifiable information.
A headless browser is a browser that operates without a graphical user interface (GUI). It functions much like a standard Chrome or any other web browser. However, it operates in the background, and you must manage it using code. This unique characteristic allows you to automate and replicate user behavior, enabling you to scrape websites that require such interaction.
Selenium is one of the most popular tools for automating web browsers. It lets you use Python, JavaScript, and a few other programming languages to customize a headless browser. Selenium can upload files, fill forms, navigate dropdown menus, and click buttons. Overall, it's a powerful tool for interacting with JavaScript elements to scrape dynamic and feature-rich websites and avoid detection, CAPTCHAS, and IP bans.
Handling AJAX Calls
AJAX calls pose an additional challenge for web scraping because they limit access to available content. This technology allows websites to update information in the background without reloading. Because of this, web scrapers that focus on HTML capture may skip updated elements because they do not register background events.
Once again, a headless browser is a viable tool for initiating AJAX calls and capturing data. Alternatively, you can inspect the developer's tools within the browser you use to identify the AJAX calls that handle your required data. You can customize a web scraper to monitor them if you have sufficient coding knowledge.
Using RESTful APIs
An API is a web scraping alternative, but sometimes, you can find the two collaborating. A Representational State Transfer Application Programming Interface (RESTful API) is a tool to streamline data exchange between two parties. It utilizes the standard HTTP protocol GET, POST, PUT and DELETE methods to share data in JSON and XML data formats. RESTful APIs are highly customizable and scalable.
You may encounter businesses using RESTful APIs to provide web scraping data to their clients. This way, you don't have to worry about web scraping tools and can focus solely on data analysis. It's worth noting that web scraping APIs are two different things that some enterprises combine.
Proxy and CAPTCHA Handling
IP bans and CAPTCHAs are two popular methods of restricting web scraping access. Firstly, we recommend carefully reviewing the Robot.txt file to familiarize yourself with website data-sharing rules. If you send too many simultaneous requests or scrape the web during peak traffic hours, you may start getting CAPTCHAs or an IP ban.
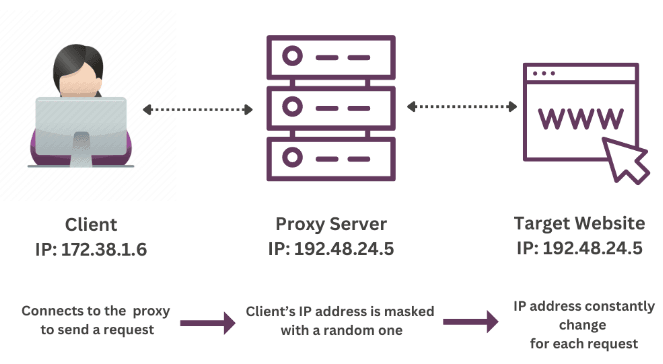
However, you can turn to proxies if your IP gets banned. They will obfuscate your original IP and issue a substitute so you can continue scraping the web. Simultaneously, there are numerous third-party services to neutralize CAPTCHAs, whether solving them or avoiding them in the first place.
Conclusion: Best Practices for Effective Web Scraping
Web scraping is one of the best ways to extract data online, but it is also challenging. Choosing the right tools and knowing the website structure will help you immensely, but you must also remain respectful of their scraping policies.
To be on the safe side, remember
- Inspect the Robot.txt and Terms of Service files to familiarize yourself with data-sharing rules
- Avoid overwhelming web servers with high-scraping frequency
- Ensure data quality and accuracy whenever you feel ready to share scraped data analysis results.


