

Let’s be honest - web scraping is not what it used to be. The web has turned into a fortress. Everywhere you look, sites are fighting back against bots. Even Cloudflare, the biggest name in internet infrastructure, now helps websites block AI crawlers by default.
It’s getting harder to extract data. If you want to stay in the game, Selenium web scraping with Python is a great place to start.
In this article, you’ll see how to collect data from dynamic websites using real web browsers without getting shut out.
What is Selenium and why use it for web scraping?
Selenium has been around for a while. It started as a browser automation framework for testing web applications using Selenium WebDriver, its core engine for controlling browsers.
With Selenium WebDriver, you can click buttons, fill out forms, scroll pages, and locate elements. Anything you can do in a browser, you can do with code.
So then, why would you use Selenium for web scraping? Why reach for a tool that wasn’t built for this job?
Most websites today don’t load all at once. They build the page as you go. Selenium gives you access to what the browser actually sees after everything has finished loading.
You’re also working against aggressive defenses. Cloudflare, PerimeterX, BotGuard, and other anti-bot tools fingerprint browsers and block bots on sight. However, when you use Selenium to control a headless browser together with proxies and human-like behavior, you get a fighting chance.
Plus, data doesn’t always sit in plain sight. Some scraping tasks require clicks, scrolls, or pop-ups to reveal the right content. A Selenium-powered web scraper can handle those cases, too.
Setting up your Selenium scraper
You’ve seen why Selenium remains a key player in the web scraping game. The truth is, most sites won’t just hand over data anymore. You have to look and act like a human, or you’ll get blocked.
We’re going to walk through building a simple Selenium scraper that extracts book titles, reviews, prices, and availability from the first three categories of Books to Scrape. It’s basic, but the structure will help you take on tougher scraping tasks down the line.
The goal is flexibility. You’ll learn how to set up clean, adaptable code that can extract data from real dynamic websites while staying one step ahead of the usual roadblocks.
Ready? Let’s begin.
Step 1: Install Python
First things first: check if Python is working. Open your terminal and run:
python --version
If you see Python 3.x.x, you’re ready to roll. If not, grab it from python.org, install it, and rerun the check.
Step 2: Install Selenium
The next step is to install a Selenium WebDriver on your machine. This is the engine that lets you control real web browsers and automate scraping tasks.
pip install selenium
That’s it. Run the command, wait for the installation to finish, and you’re ready to move on.
Step 3: Install undetected-chromedriver
You’ll need one more piece to stay stealthy: undetected-chromedriver. It’s a smart wrapper for Selenium’s Chrome WebDriver that patches fingerprints, spoofs headless browsers, and helps you scrape without tipping off defenses.
pip install undetected-chromedriver
Run the install. This is what lets you blend in and extract data without constant blocks. That’s the setup done. Now you can move on to writing web scraping code that collects data even when sites throw everything they’ve got to stop you.
Get your workspace ready
You’ve got the tools. Now it’s time to lay the groundwork. Open your terminal, head to the folder where you’ll keep this project:
cd Desktop
Make a new folder:
mkdir “Selenium Web Scraper”
Then step into that folder:
cd Selenium Web Scraper
Now, create the Python file:
echo.> Seleniumwebscraper.py
Pop it open in your favorite editor and let’s build.
Start building your Selenium web scraper
We’re going to write a Selenium scraping script that pulls data from Books to Scrape, one category at a time. You’ll learn how to extract data like star ratings, titles, and availability without triggering defenses or leaving fingerprints.
We’ll start simple: open the site, click the 'Travel' category, scrape the book data, and then close out. Next, we’ll switch everything, including the browser, proxy, and identity, then repeat the process for 'Mystery' and 'Historical Fiction' categories.
The reason we break it up is simple. The longer you sit on a page or hammer through categories, the more likely you are to trip alarms. With Selenium, headless browsers, and smart session rotation, you can scrape dynamic content in stages, keeping your web scraping tasks cleaner and stealthier.
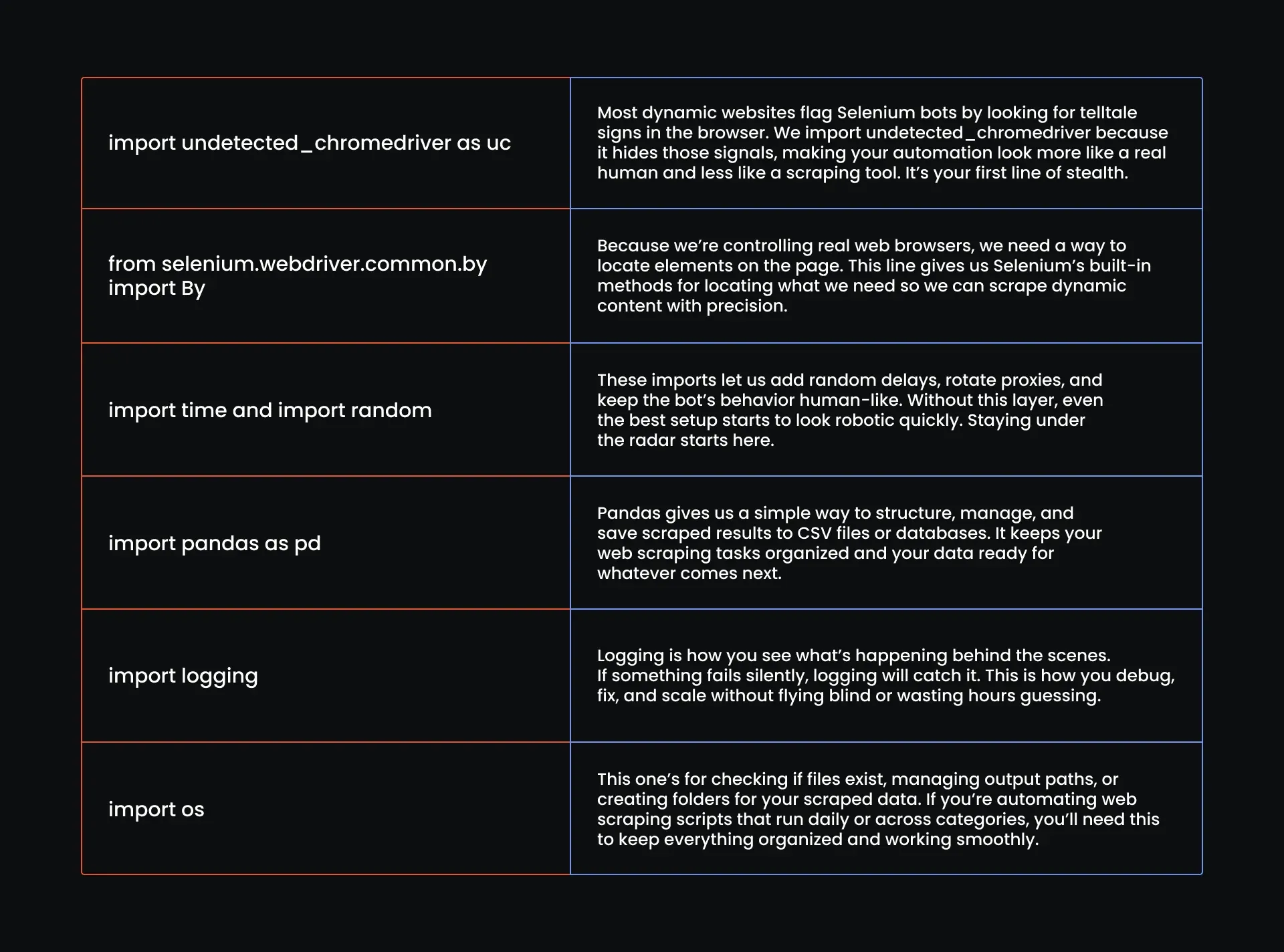
Step 1: Write your import statements
First step: import the essentials. Here is what we need:
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import time
import random
import pandas as pd
import logging
import os
Here is what all that means:
Step 2: Set up your logging system
The next step is setting up Python’s built-in logging system. Logging gives you visibility into what your code is doing while it runs. Here’s what each logging level means:
- DEBUG: ultra-detailed messages for deep troubleshooting
- INFO: routine updates on scraping tasks
- WARNING: signals something unusual but not fatal
- ERROR: reports when something breaks
- CRITICAL: flags total failures that may stop everything
We’ll use the INFO level here. It keeps your web scraping script transparent without overwhelming you with too much technical details. If you ever need to debug connection drops or missing elements, bump it up to DEBUG.
logging.basicConfig(level=logging.INFO, format='[%(asctime)s] %(message)s')
Step 3: Add your proxies
Proxies are non-negotiable for web scraping, especially when targeting dynamic websites with anti-bot defenses. Books to Scrape is fine without them, but any site with aggressive anti-bot rules will rate-limit or block you fast. Every request from the same IP chips away at your cover until you’re locked out.
For this setup, we’ll use MarsProxies rotating Residential Proxies. One clean endpoint keeps it simple, and MarsProxies handles the IP rotation for us. But for larger scraping tasks, you’ll need at least two sticky IPs per page from diverse locations. That way, you hit each page fresh and keep better control. Check our Amazon web scraping guide for deeper examples.
Here is our rotating residential proxy endpoint from MarsProxies:
PROXIES = [
"http://ultra.marsproxies.com:44443",
# Add more proxies if you have them
]
Undetected-chromedriver can be tricky when it comes to authenticating proxies with a username and password. The smoother move is to whitelist your IP address at the provider level. That way, your sessions stay clean. For a full walkthrough on how to whitelist, check out our dedicated guide on how to use MarsProxies Residential proxies.
Step 4: Add your user agents
The next thing you need is user agents. For something light like Books to Scrape, a handful of user agents is enough. But real-world web scraping targets like Amazon or Best Buy will flag you fast if you do not handle this right.
Modern websites use layered detection. They check not just your user agent string but your entire browser fingerprint: screen size, timezone, language, WebGL, Canvas, and hardware details. Mismatches like claiming to be on an iPhone while sending desktop behavior get caught immediately.
The fix is complete alignment. Pair each user agent with the correct screen size, timezone, language, and GPU profile. You want a browser that looks and behaves like the identity you claim.
Here is our user agent code block:
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36",
]
We’re using Windows, Mac, and Linux user agents because they are the most common fingerprints in real web browsers. All three share Chrome 125, a stable release that matches what real users run today.
Just a quick recap, this is how your script should look like by this point:
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import time
import random
import pandas as pd
import logging
import os
# Logging Setup
logging.basicConfig(level=logging.INFO, format='[%(asctime)s] %(message)s')
# Proxies and User-Agents
PROXIES = [
"http://ultra.marsproxies.com:44443",
# Add more proxies if you have them
]
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36",
]
Step 5: Set up undetected-chromedriver
Undetected-chromedriver is the brain of your Selenium stack. If you’ve scraped any serious dynamic page, you know this can make or break you. The tool alone won’t save you. It only keeps you under the radar if you control every fingerprint it leaks.
For Books to Scrape, this is overkill. But for anything behind heavy defenses, you need to spoof everything just to get through the door. Here’s what you lock down:
- Rotate user agents
Real users don’t all run the same Chrome browser build. Your scraper needs to rotate between realistic, current user agents that match what people actually use. This is non-negotiable for modern web scraping.
- Set the screen size
Your screen size must match your user agent. An iPhone claim paired with a 1920x1080 resolution will trip alarms instantly. Sites cross-check this because real devices and browsers always align. Make sure yours do, too.
- Set the language
Language headers tell the site what language your browser “speaks.” Leaving this blank or inconsistent is a sure way to stand out as a bot. Always set your language explicitly: --lang=en-US,en is a safe default.
- Set the timezone
Your timezone has to line up with your proxy location. If your IP points to India but your browser reports Eastern U.S. time, the mismatch gives you away. Your timezone should always sync with your proxy’s location to avoid detection.
- Headless mode
Bots love headless mode, and sites know it. Some detection systems block headless browsers automatically. Whenever possible, run in full browser mode. Yes, it is slower, but it makes you look more human. Use headless only when stealth is less important than speed.
Not every web scraping job calls for maximum stealth. Start here, then add what you need. If the site is easy, this gets the job done. If defenses tighten, tweak your user agents to extract data without tipping them off.
# Driver Setup
def create_driver(proxy, user_agent):
options = uc.ChromeOptions()
options.add_argument(f'--proxy-server={proxy}')
options.add_argument(f'user-agent={user_agent}')
options.add_argument('--no-sandbox')
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument('--lang=en-US,en')
driver = uc.Chrome(options=options)
driver.execute_cdp_cmd('Network.setUserAgentOverride', {"userAgent": user_agent})
return driver
Let's break this down:

Step 6: Write your scraping logic
With the setup done, you can now focus on scraping data. The process needs two parts: one function to extract data from the page and another to control how we scrape. We’ll start with the extraction, grabbing the titles, prices, and other details from the dynamic content.
Before you can extract data, you need to see how the site is built. This helps you know which elements your function will target. For context, we’re interested in four things:
- The title of the book
- The price
- The availability
- The star rating
Let’s walk through how to find them and build a CSS selector for each.
Open the site and inspect the title
- Head to Books to Scrape
- Scroll to the first book you see
- Right-click directly on the book title (the blue link)
- In the menu that appears, click Inspect
Check the HTML structure
Look for the highlighted HTML. You’ll see something like:
<h3>
<a href="..." title="Book Title">Book Title</a>
</h3>
This CSS selector shows you the tag (h3) and the element (a) where the title is stored.
Locate the star rating
While still inside the same product card, look above the title. You’ll see something like:
<p class="star-rating Three"></p>
This tells us that the rating is hidden inside the class name (Three, Four, etc.).
Find the price
Move down in the HTML until you see:
<div class="product_price">
<p class="price_color">£51.77</p>
</div>
That’s where you’ll extract the price from the text inside the p.price_color.
Check availability
While still inside the same product_price div, you’ll find:
<p class="instock availability">
In stock
</p>
This is where you pull the availability status (“In stock” or not). Now, we can use this information to build our code below:
# Extract Book Details
def extract_books(driver):
books = []
cards = driver.find_elements(By.CSS_SELECTOR, 'article.product_pod')
for card in cards:
try:
title = card.find_element(By.TAG_NAME, 'h3').text.strip()
price = card.find_element(By.CLASS_NAME, 'price_color').text.strip()
availability = card.find_element(By.CLASS_NAME, 'availability').text.strip()
star_element = card.find_element(By.CSS_SELECTOR, 'p.star-rating')
star_rating = star_element.get_attribute('class').split()[-1]
books.append({
'title': title,
'price': price,
'availability': availability,
'star_rating': star_rating
})
except Exception as e:
logging.warning(f"Skipping book due to error: {e}")
continue
return books
Here is what all that means:

Next, you need a function that controls how you scrape each page. This function spins up a fresh browser session with a random proxy and user agent, loads the target URL, and calls your data extraction logic to pull the details. If it finds data, it saves it to a CSV. If not, it logs the issue, waits a bit, and tries again.
Here is the function:
# Scrape a Single Page with Fresh Identity Each Time
def scrape_page(url, output_file, max_retries=3):
for attempt in range(max_retries):
proxy = random.choice(PROXIES)
user_agent = random.choice(USER_AGENTS)
driver = create_driver(proxy, user_agent)
try:
driver.get(url)
time.sleep(random.uniform(3, 6))
books = extract_books(driver)
if books:
df = pd.DataFrame(books)
file_exists = os.path.isfile(output_file)
df.to_csv(output_file, mode='a', index=False, header=not file_exists)
logging.info(f" Extracted {len(books)} books from {url}")
break
else:
raise ValueError("No books extracted.")
except Exception as e:
logging.error(f" Attempt {attempt + 1} failed: {e}")
time.sleep(random.uniform(2, 5))
finally:
driver.quit()
logging.info("Session closed.")
Let's look at how it works:

Step 7: Write your main execution layer
With your scraping logic in place, it’s time to map out the categories you’ll scrape. This structure lets you assign one or more URLs to each category. Every URL runs in a clean browser session with a fresh proxy and identity, helping you scrape data safely from dynamic web pages without leaving fingerprints.
Here is the code:
# Main Execution: Rotate Identity Per Page
categories = {
'Travel': [
'http://books.toscrape.com/catalogue/category/books/travel_2/index.html',
# Add page 2, page 3 URLs if needed
],
'Mystery': [
'http://books.toscrape.com/catalogue/category/books/mystery_3/index.html',
# Add more pages if needed
],
'Historical Fiction': [
'http://books.toscrape.com/catalogue/category/books/historical-fiction_4/index.html',
# Add more pages here too
],
}
With your categories and URLs set, the last piece is the execution layer. This is where you tell Selenium WebDriver to loop through each category and scrape data from every URL.
for category, urls in categories.items():
output_file = f'{category.lower().replace(" ", "_")}_books.csv'
for url in urls:
scrape_page(url, output_file)
This part sets the file name for each category, like travel_books.csv or mystery_books.csv, so your data stays organized. Then, it loops through every URL you defined, spinning up a fresh browser session with a new proxy and user agent each time to safely scrape data.
Here is your full Selenium scraping script:
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import time
import random
import pandas as pd
import logging
import os
# Logging Setup
logging.basicConfig(level=logging.INFO, format='[%(asctime)s] %(message)s')
# Proxies and User-Agents
PROXIES = [
"http://ultra.marsproxies.com:44443",
# Add more proxies if you have them
]
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Safari/537.36",
]
# Driver Setup
def create_driver(proxy, user_agent):
options = uc.ChromeOptions()
options.add_argument(f'--proxy-server={proxy}')
options.add_argument(f'user-agent={user_agent}')
options.add_argument('--no-sandbox')
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument('--lang=en-US,en')
driver = uc.Chrome(options=options)
driver.execute_cdp_cmd('Network.setUserAgentOverride', {"userAgent": user_agent})
return driver
# Extract Book Details
def extract_books(driver):
books = []
cards = driver.find_elements(By.CSS_SELECTOR, 'article.product_pod')
for card in cards:
try:
title = card.find_element(By.TAG_NAME, 'h3').text.strip()
price = card.find_element(By.CLASS_NAME, 'price_color').text.strip()
availability = card.find_element(By.CLASS_NAME, 'availability').text.strip()
star_element = card.find_element(By.CSS_SELECTOR, 'p.star-rating')
star_rating = star_element.get_attribute('class').split()[-1]
books.append({
'title': title,
'price': price,
'availability': availability,
'star_rating': star_rating
})
except Exception as e:
logging.warning(f"Skipping book due to error: {e}")
continue
return books
# Scrape a Single Page with Fresh Identity Each Time
def scrape_page(url, output_file, max_retries=3):
for attempt in range(max_retries):
proxy = random.choice(PROXIES)
user_agent = random.choice(USER_AGENTS)
driver = create_driver(proxy, user_agent)
try:
driver.get(url)
time.sleep(random.uniform(3, 6))
books = extract_books(driver)
if books:
df = pd.DataFrame(books)
file_exists = os.path.isfile(output_file)
df.to_csv(output_file, mode='a', index=False, header=not file_exists)
logging.info(f" Extracted {len(books)} books from {url}")
break
else:
raise ValueError("No books extracted.")
except Exception as e:
logging.error(f" ] Attempt {attempt + 1} failed: {e}")
time.sleep(random.uniform(2, 5))
finally:
driver.quit()
logging.info("Session closed.")
# Main Execution: Rotate Identity Per Page
categories = {
'Travel': [
'http://books.toscrape.com/catalogue/category/books/travel_2/index.html',
# Add page 2, page 3 URLs if needed
],
'Mystery': [
'http://books.toscrape.com/catalogue/category/books/mystery_3/index.html',
# Add more pages if needed
],
'Historical Fiction': [
'http://books.toscrape.com/catalogue/category/books/historical-fiction_4/index.html',
# Add more pages here too
],
}
for category, urls in categories.items():
output_file = f'{category.lower().replace(" ", "_")}_books.csv'
for url in urls:
scrape_page(url, output_file)
To run your code, just head back to the terminal session we created earlier and run this command:
python Extractor.py
Here is the output:
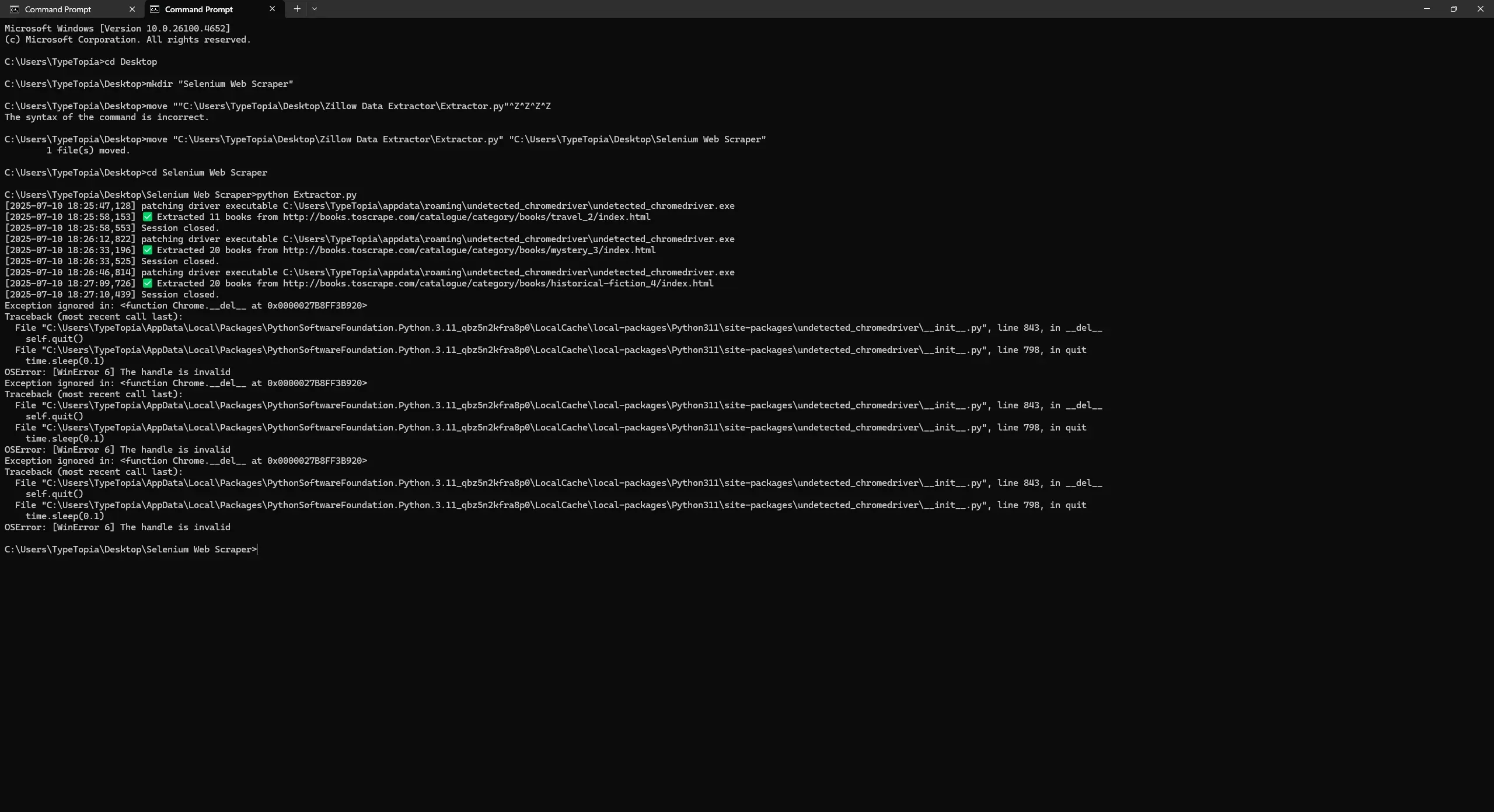
The script worked exactly like we built it. It loaded three clean sessions, extracted the data from each category, and saved them to separate CSV files. But let’s not kid ourselves. Books to Scrape is friendly.
Real-world scraping, especially on major sites, is a different beast. Anti-bot defenses today are more challenging, and your scraping script needs more care. Let’s talk about what can go wrong.
Common issues with Selenium web scraping
The reason web scraping has become so hard is simple: AI changed the game. Companies like OpenAI scraped billions of pages, building models that use content scraped without asking. Publishers noticed. They saw their work used, repackaged, and monetized by systems they never agreed to feed.
So they fought back hard.
Now, when you run your custom Selenium scraper on dynamic pages, you’re stepping into a world shaped by that backlash. If you want to scrape data today, you need to expect pushback and build your scraping script to survive it.
Below are some of the common issues to expect when scraping real websites:
- Sometimes, your web scraping script runs perfectly. The logs look good, the session closes cleanly, and everything seems fine until you open the CSV and it’s empty. That’s a soft block. The site served you fallback content meant for bots: empty containers, placeholders, or stripped data. Add logic that checks if real content is actually present before moving forward, so you don’t waste time scraping nothing.
- Next, check your fingerprint. Rotation is key, but sloppy rotation gets you flagged. If your proxy says France, your user agent says iPhone, your screen is desktop-sized, and your timezone says New York, you’ve already lost. The site sees the mismatch, soft-blocks you, and leaves you debugging the wrong thing. Keep your fingerprint consistent across every web scraping stack.
- Your proxy pool matters just as much. Random IPs from random places set off alarms. Scaling Selenium safely means building a clean, diverse proxy rotation strategy that stays consistent with your behavior profile. Residential Proxies, especially from MarsProxies, help here because they look like real users. They’re resilient and far less likely to get you blocked when running web scraping scripts on serious websites.
- Finally, pay attention to how your bot behaves. Don’t hit the page and start scrolling instantly. Some sites delay dynamic content on purpose, waiting for that telltale robotic scroll. If you move too soon, you’ll scrape an empty page forever. Mix in clicks, hovers, scroll pauses, along with anything else that looks human. The goal is to blend in while loading the content.
When not to use Selenium for web scraping
By now, you know Selenium is powerful. But you don’t call Superman when the local police department can handle a minor incident. Let’s break down the moments when Selenium is not your best move:
- When the website is static
If you can open 'View Page Source' and see the data right there, you’re dealing with a static site. You don’t need Selenium WebDriver for static web scraping. Stick with traditional scraping tools like requests and BeautifulSoup. It’s faster, lighter, and less likely to get you blocked. We cover this traditional web scraping setup in our Python web scraping guide.
- When there are better alternatives
Check the Network tab first. Some dynamic sites load data through JSON APIs that you can tap directly. It’s faster, cheaper, and more reliable than spinning up browsers and simulating user interactions. Save Selenium for when no other option is available. For more strategies on web scraping tools and strategies, see our guide on web scraping techniques.
- When you’re scraping at scale
Need to scrape thousands of pages? Selenium isn’t built for that. Scaling Selenium across hundreds of sessions takes serious infrastructure. If your use case is high volume, consider tools designed to scale cleanly from the ground up. A good example is Scrapy, a framework designed for scale.
Best practices and legal considerations
Here are a few best practices and legal considerations you need to keep in mind.
- Respect robots.txt
Robots.txt is a simple file that tells bots which parts of a website are off-limits. It is not legally binding, but ignoring it can get you blocked, banned, or even sued, especially if your web scraping job involves restricted or sensitive content. Always check it before you scrape.
- Avoid rate-limiting bans
We have already covered the technical side: proxies, rotating user agents, smart delays, and behavior that looks human. Stick to those rules every time. Scraping data without them is like walking into a trap with your eyes closed.
- Legal boundaries and ethical scraping
Know the difference between public and private data. Public-facing pages are usually fair game. But scraping behind logins, paywalls, or using hacks is illegal in most places. Stick to what is visible to any user without requiring a login.
Final thoughts
We hope this guide helped you build a working Selenium scraping setup with undetected-chromedriver. Most dynamic pages will not be as forgiving as Books to Scrape. But with the right setup, smart rotation, and careful moves, you’ll stay one step ahead when scaling Selenium.
If you want to swap ideas with other developers and scrapers who know how tough modern websites really are, join our Discord and become part of the conversation.
Is Selenium web scraping legal?
Web scraping is not illegal when you scrape public websites. The line gets crossed when you scrape private data, like content behind logins, paywalls, or protected systems. Always stick to scraping data that any user can see without special access.
Is Selenium better than BeautifulSoup?
It depends on the web scraping job. Selenium WebDriver is more powerful because it controls web browsers, perfect for dynamic sites. But it is slower and heavier. BeautifulSoup is better for static pages, where you can scrape in bulk without browser automation.
Is Selenium web scraping free?
Yes, Selenium itself is free to use. But web scraping at scale usually means paying for extras like proxies, servers, and sometimes anti-detection tools to keep your scraping scripts stable and unblocked.
Which browser is best for Selenium web scraping?
Chrome is the top choice for web scraping with Selenium. It’s stable, well-supported, and works smoothly with tools like undetected-chromedriver. For stealth scraping on dynamic pages, sticking with Chrome keeps things consistent and less likely to break.


