

So, you’re into real estate stuff but also an avid big data enthusiast? While we’re not mind readers, we’re pretty sure you thought about collecting data from Zillow quite a few times. Anyhow, whether you’re after the current market trends, comparing listings across retailers, or simply looking for ways to generate leads, having access to real-time real estate data is a valuable asset.
Today is your lucky day as we’ll help you learn how to build a Zillow scraper using Python, walk through the essential tools you’ll need, and explore advanced techniques to scale and automate your scraping operations efficiently.
Understanding Zillow's website structure
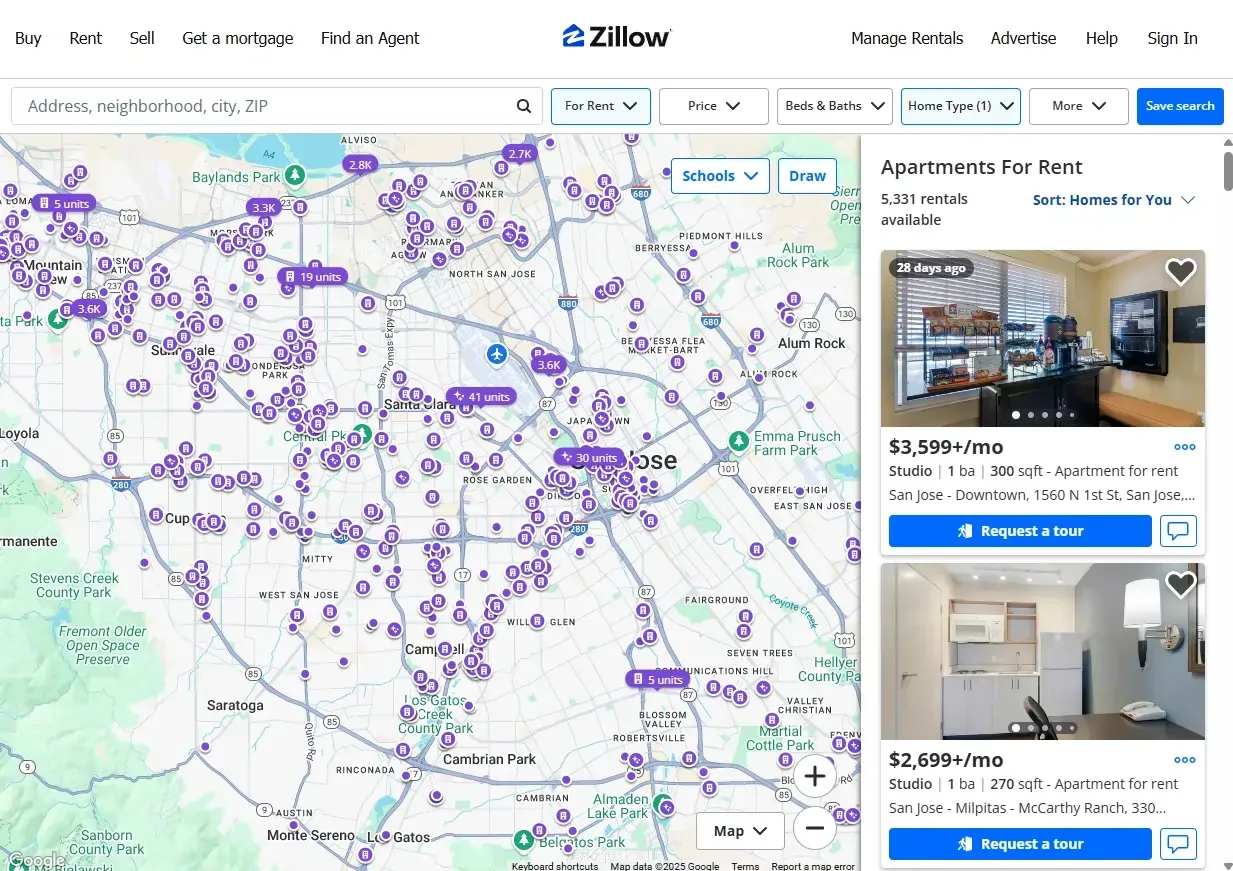
Before diving into the more complex aspects (code, of course), we must first understand how Zillow’s website is structured and how it delivers the real estate data that we’re after.
Frontend structure
Zillow's website is divided into several types of pages, but the two most relevant are:
- Search results pages: These pages show lists of properties filtered by criteria such as price, location, or number of bedrooms.
- Property Detail Pages: When you click on a listing, you land on a page with comprehensive information about that specific property.
Each of these page types contains structured data that is either rendered statically or loaded dynamically. Understanding the layout of these pages is crucial to successful web scraping Zillow content.
JavaScript-rendered content
Much of Zillow’s content is dynamically loaded via JavaScript after the initial page load. This means you won’t find the data you want by just looking at the raw HTML, especially when using libraries like requests. Instead, you need to either locate embedded JSON or use a headless browser to render the page fully before parsing.
Using browser developer tools
To identify the data source:
- Open a Zillow search page in Chrome or Firefox.
- Right-click a property card and choose "Inspect" to open the developer tools.
- Go to the Network tab and filter by XHR to find any JSON API requests.
- Alternatively, explore the Elements tab and look for <script type="application/json"> tags that contain embedded data.
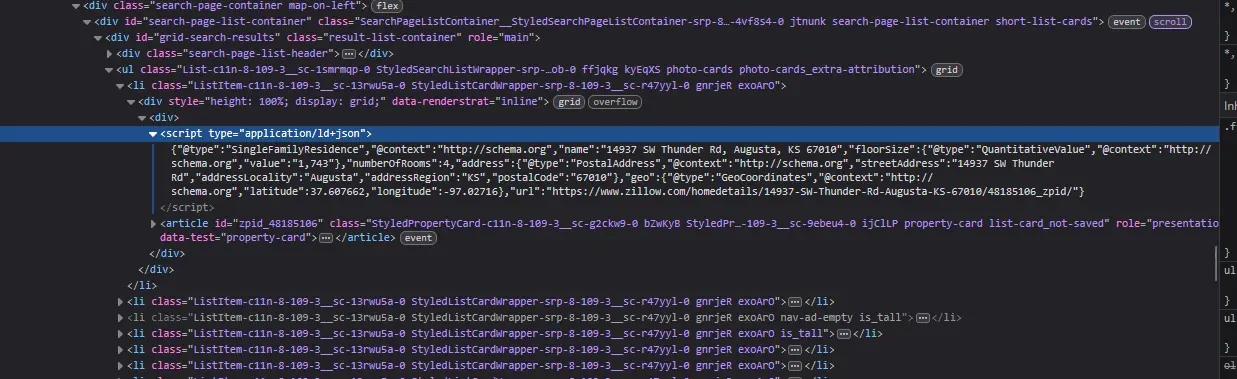
Extracting this embedded data gives you a more stable and structured source compared to scraping visible HTML content
Tools and technologies for Zillow scraping
To successfully extract data from Zillow, you will need the right herbs, spices, sauces, and all that. Well, not really. It's more like relevant tools and technologies, depending on your scraping goals.
Programming languages and libraries
Python is a widely used language for web scraping due to its robust ecosystem and ease of use. Here are some key libraries:
- requests: Handles HTTP requests to fetch HTML content.
- BeautifulSoup: Parses and navigates HTML and XML content.
- lxml and parsel: Provide XPath and CSS selector support for fast parsing.
To install all of them at once, use this command:
pip install requests beautifulsoup4 lxml parsel
These libraries allow you to extract real estate data from Zillow search results and property detail pages effectively.
Headless browsers
For content rendered via JavaScript, consider headless browsers:
- Selenium: Automates web browser interaction to load full pages.
- Playwright: A modern and faster alternative that supports multiple browsers and contexts.
These tools are essential for scraping Zillow listings where data appears after JavaScript execution.
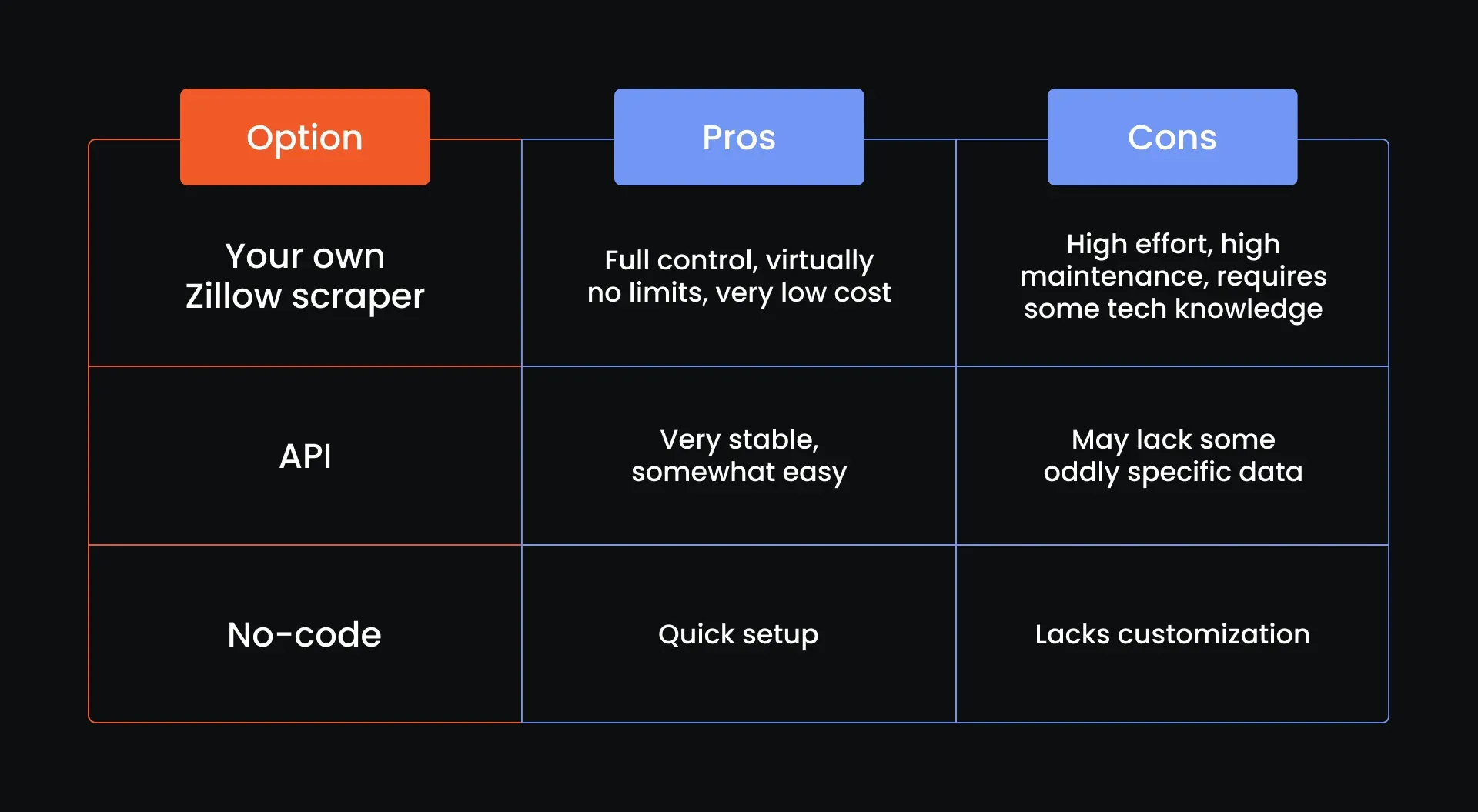
API-based solutions
You can also leverage third-party APIs that abstract the scraping for you:
- Apify: Offers a Zillow Scraper Actor that provides structured output with support for pagination, filtering, and more.
These services reduce development effort but may come at a considerable cost or have ridiculous data limitations.
No-code tools
For users without a programming background, no-code scraping tools can be a lifesaver:
- Octoparse: Drag-and-drop interface with scheduling and export options.
- ParseHub: Allows for visually selecting elements and supports conditionals and loops.
These tools simplify scraping Zillow data but lack the flexibility of code-based approaches.
How to build a Zillow scraper with Python
Now, let’s get to the main course and what you’ve been waiting for – how to build a Zillow scraper that’s based on Python to get all that juicy real estate data!
Step 1: Setting up the environment
It all starts with essentials:
pip install requests beautifulsoup4 pandas
This command will install all the required libraries (as you can tell, they are requests, BeautifulSoup, and Pandas)
Now, as you may recall, Zillow’s website structure includes JavaScript-rendered content. In order for your scraper to understand it, you will need a headless browser. Let’s go for Selenium in this case and use this command:
pip install selenium
Optionally, you can also set up a virtual environment for easier package management.
Step 2: Fetching search results
Zillow URLs include search filters such as location, price range, and home type. Example:
base_url = "https://www.zillow.com/homes/for_sale/Los-Angeles,-CA_rb/"
Use requests or Selenium to access the page.
Step 3: Parsing property listings
Zillow often includes structured data as embedded JSON within <script> tags:
from bs4 import BeautifulSoup
import requests
import json
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(base_url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
for script in soup.find_all('script'):
if 'application/json' in script.get('type', ''):
json_data = script.string
break
parsed = json.loads(json_data)
Look for sections like searchResults or listResults in the JSON structure to extract:
- Address
- Price
- Beds/baths
- Listing URLs
Step 4: Accessing detailed property information
Follow each listing URL to get more property data. Look for:
- Tax history
- Year built
- Lot size
- Interior features
Use similar parsing techniques or headless browsers if necessary.
Step 5: Handling pagination
Zillow paginates its results, and URLs usually include a traditional page or pagination segment:
for page in range(1, 10):
url = f"https://www.zillow.com/homes/for_sale/Los-Angeles,-CA/{page}_p/"
# fetch and parse each page
Important note: always bear in mind rate limits and include delays between requests to avoid bans and keep scraping Zillow without anyone knowing.
Step 6: Data storage
Store your results in accessible formats:
import pandas as pd
df = pd.DataFrame(property_list)
df.to_csv("zillow_data.csv", index=False)
df.to_json("zillow_data.json")
You can also use databases like SQLite for local storage or connect to remote databases for scaling.
Advanced Scraping Techniques
Bypassing anti-scraping measures
Just like any other website under the Internet’s sun, this real estate listing website may block suspicious traffic when it suspects you of scraping. To lessen the risk of it happening, try:
- Rotating proxies with reliable providers like MarsProxies.
- Spoofing headers with varied User-Agents.
- Adding randomized sleep delays.
To add user agents’ headers and delays, try this command:
import random, time
user_agents = ["UA1", "UA2", "UA3"]
headers = {"User-Agent": random.choice(user_agents)}
time.sleep(random.uniform(2, 5))
Managing JavaScript-rendered content
Use headless browsers (in this case, Selenium) to extract fully loaded data:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
driver.get(base_url)
data = driver.page_source
driver.quit()
Optimizing for performance
You can rev up the speed of scraping by using asynchronous or multithreaded methods:
- asyncio + aiohttp for concurrent HTTP calls.
- Python threading for handling multiple pages simultaneously.
This can be achieved by using the following:
import asyncio
import aiohttp
async def fetch(session, url):
async with session.get(url) as resp:
return await resp.text()
Monitoring and maintenance
Things don’t tend to remain stable forever, and Zillow is not an exception. Since their structure may change, set up the following:
- Logs to catch unexpected failures.
- Alerts for parsing errors.
- Tests that validate key selectors and data fields regularly.
Scaling your Zillow scraper
Cloud deployment
Deploying your scraper to various cloud platforms is a very efficient way to scale up your Zillow scraper to new heights. You can try these options out to check which one suits you best in accordance with your needs:
- AWS Lambda or EC2 for event-based or persistent jobs
- Google Cloud Functions or App Engine
- Azure Web Apps for hosting web scrapers with scheduling support
Scheduling and automation
Automation is another cornerstone of any efficient scraper operation. To engage in it, use the following:
- Use cron jobs (crontab -e on Linux)
- Windows Task Scheduler
- Tools like Airflow for complex ETL workflows
Data pipeline integration
Finally, integrate your data output into:
- PostgreSQL or MongoDB
- Cloud storage (S3, GCS)
- Analytics tools like Power BI or Tableau for dashboards
Alternatives to building your own Zillow scraper
If this seems a little bit too difficult, time-consuming, or you just don’t feel like building your own scraper for scraping Zillow, there are quite a few alternatives available.
If you prefer ready-to-use data, these APIs might help:
- Zillow Bridge API (official, but SO VERY limited)
- Estated: Offers parcel-level data and property analytics.
- Mashvisor: Focused on real estate investors with market trends.
You can also use existing tools or hosted services:
- Apify's tool for scraping Zillow
- Scrapy spiders hosted on Scrapy Cloud or AWS
Let’s compare all of the ways to get into Zillow scraping:
Conclusion
Scraping Zillow data can open doors to valuable insights and business opportunities in the real estate space. Whether you're gathering pricing trends, compiling property datasets, or creating lead generation tools, building a Zillow scraper in Python provides you with the flexibility and control you need.
We’ve explored everything from understanding Zillow’s structure to deploying scalable scraping pipelines. Whether you choose to build your own solution to real estate data scraping or leverage third-party tools, the key is staying compliant, respectful, and adaptable in the ever-changing landscape of web scraping Zillow data.
And, as always, if you are stuck somewhere or this guide made your head spin, friendly help is available on our Discord channel. Don’t be afraid, just jump in and say hello!
What types of data can I extract from Zillow listings?
You can extract all the real estate data you need from Zillow listings by scraping Zillow data. This includes price, address, number of bathrooms, number of bedrooms, lot size, year built, square footage, property tax, days on market, agent info, listing URL, and even images.
Is there an official API provided by Zillow?
Yes, the Zillow Bridge API is the official API, but it has a ridiculously limited access and use cases are minimal. Most developers turn to scraping due to restrictions.
How can I avoid getting blocked while scraping Zillow?
To minimize blocks, use rotating proxies from reliable providers, such as MarsProxies; keep changing the user agents; throttle some of the requests to mimic human behavior.
Are there any limits to how much data I can scrape from Zillow?
While Zillow doesn’t publish specific limits, frequent or aggressive scraping may trigger rate limiting or IP bans. Always scrape responsibly!


